Posts com a tag: privacy
Some thoughts on Twitter and Mastodon
2017-06-25 01:32 -0300. Tags: comp, web, privacy, freedom, life, mind, in-english
Since the last post I've been using Mastodon as my primary microblogging platform for posting, but I was still regularly reading and retweeting stuff on Twitter. A while ago Twitter started reordering tweets in my timeline despite my having disabled that option, just as I said could eventually happen (except much earlier than I expected). The option is still there and is still disabled, it's just being ignored.
Twitter brought me much rejoicing during the years I used it. I follow a lot of cool people there and I've had lots of nice interactions there. I found myself asking if I should accept some abuse from Twitter to keep interacting with those people, and I've been shocked at myself for even asking myself that. I've been using Twitter less and less as of late. (I'd like to be able to say I did it out of principles, but to be completely truthful I find the non-chronological timeline utterly annoying, and that has had as much to do with my leaving as principles.)
Although I switched to Mastodon as my Twitter replacement, Mastodon is not really "another Twitter". Having 500 rather than 140 characters to write initially felt like learning to talk again. Early on when I started using Mastodon, I was going to reply to a person's toot (that's what posts are called in Mastodon) with a short, not-really-one-full-sentence line that is the norm in Twitter. I wrote it down and was like "no, this kind of grunting a half-thought is not going to cut it here". It felt like Twitter's 140 character limit not only limited the kinds of things you could say, but also imposed/favored a "140-character mindset" of not finishing lines of thought or thinking with much depth. As I went on using Mastodon, I found myself writing thoughts I wouldn't have even tried to write in Twitter.
I still open up Twitter once in a while. Today I opened the mobile version in my desktop browser and noticed that the mobile version still shows a chronological timeline, still doesn't pollute the timeline with liked-but-not-retweeted tweets, and is much faster and cleaner than the desktop version. (I still have to un-fix the navigation bar via CSS, but I already had to do that in the desktop version anyway.) It's tempting to start using Twitter again through the mobile version, while it doesn't catch up with the new "features". I know I shouldn't, though. Even if the mobile version never caught up with the misfeatures (I suppose it eventually will, probably in short time), Twitter has already shown they're willing to throw stuff down their users' throats in the name of – what? I'm not even sure. Maybe they want to make Twitter more Facebook-like to attract Facebook users, even if that means alienating the people who used Twitter exactly because it was not like Facebook?
The funny thing is Twitter could simply provide some options for users to control their experience ("(don't) show tweets liked by your followers", "(don't) show tweets you liked to your followers", "(don't) reorder tweets" (the last one is already there, it just doesn't work)). This way they could cater to whatever new audience they have in mind and keep the users who liked how Twitter used to work. They just don't care to. I'm not really sure what are the motivations and goals behind Twitter's actions. For a really long time before the last changes it had been showing the "you might like" box (even if you clicked the "show me less like this" option (the only way to dismiss it) every time) and the "you might like to follow" box (even if you dismissed that too, and even though it also showed undimissable follow suggestions on the right pane anyway). I used to open Twitter pretty much every day, so it didn't really make sense as a user retention strategy. Maybe they want to incentivize people to do specific things on Twitter, e.g., throw in more data about themselves? (Yeah, there was the "add your birthday to your profile" periodic thing too.)
Meh.
Why the new like-based Twitter timeline is terrible
2017-05-31 21:56 -0300. Tags: comp, web, privacy, in-english
Recently, tweets which people I follow 'liked' (but not retweeted) started showing up in my Twitter timeline. Twitter had been showing the "you might like" box with such tweets for quite a long time, but they were separate from normal tweets, and you could dismiss the box (it would come back again after a while, though). Now those 'liked' tweets are showing up intermingled with the normal tweets, and there is no option to disable this.
Now, Twitter has been working hard on its timeline algorithms lately, and, at least initially, the liked tweets it added to my timeline were indeed stuff I liked, and they constituted just a small part of total tweets. That's not the case anymore: now liked tweets seem to be about one third of all tweets I see, and a smaller proportion of them interest me. Moreover, I simply don't want to see that many tweets. If I'm seeing all tweets I used to see plus liked tweets, and liked tweets comprise about a third of all tweets I see now, then I'm seeing about 50% more tweets, and I simply don't have the patience for so much tweetering; I already limit the number of people I follow so as to keep my timeline manageable.
But even if Twitter's algorithms were perfect and showed me only things I wanted to see in an ideal quantity, showing liked-but-not-retweeted tweets would already be bad, for a number of reasons:
'Likes' (formerly 'favorites') were a way to give fake Internet points to someone without being forced to share it with your followers. Sometimes I do this just because I don't think the content will be generally of interest to my followers (e.g., linguistics-based humor). But sometimes I may do it for more serious reasons, for instance, because I think the content might be offensive or be taken badly by some of my followers (e.g., religion-based humor). And sometimes I want to signal an approval to someone's opinion which might generate controversy or discussion if shared, but I don't really want to have a discussion about it with anyone at the time (e.g., some political views).
Likes have always been public in the sense that you could open up someone's profile and see a feed of everything they liked, but you had to actively stalk someone to see that. Now people who follow you don't have to do anything in particular to see the things you liked, so you have to work on the assumption that anything you like might show up in someone else's feed, which is annoying.
You don't see every tweet your followees liked; you only see some of them, and the selection is done by Twitter's algorithms, which of course are closed. At best (if the algorithms try to maximize showing things you like), this has the potential of creating a bubble effect of feeding you more and more with the things you already like and agree with, and filtering out differing views and opinions. At worst, the algorithms might try to maximize something else (e.g., things advertisers would like you to see rather than things you would like to see).
The bubbling effect is currently probably not as bad in Twitter as it is in Facebook because you still see all tweets your followees (re)tweet; you just see more tweets on the top of those. Note that Twitter already has an option of using a more Facebook-like timeline which reorders the tweets according to what its algorithms think you might be interested in more. It is currently opt-out, but it might stop being so in the future, the same way you used to be able to dismiss the "you might like" tweets but can't anymore.
As Twitter keeps trying brave new ways of monetizing its users, it's probably going to become more problematic from a privacy perspective. Meanwhile, we now have a quite viable decentralized, free, and usable social network (and I'm already there). The sad thing is that most of the people I follow will probably not migrate from Twitter, but as Twitter keeps getting worse in matters of privacy, transparency and usability, I'm becoming more inclined to leave it, as I have done before.
Update (2017-06-13): Today my Twitter timeline showed up out of order, at least temporarily, even though the "Show me the best Tweets first" options still appears disabled. That one came quick.
Como evitar que Google, Facebook, Twitter e a NSA saibam por onde você anda na Web
2013-07-13 22:53 -0300. Tags: comp, web, privacy, em-portugues
Agora que é um fato público e conhecido que os dados que você entrega ao Google, Facebook e companhia não estão em boas mãos (e se você acha que está tudo bem, queira assistir um videozinho), pode ser uma boa você reduzir a quantidade de informação a que eles têm acesso.
E graças aos botões de "Curtir", "Tweet", "+1" e similares, bem como as propagandas do Google, o Google Analytics, e o uso extensivo do googleapis.com, essas empresas recebem informação suficiente para ter uma boa idéia de por onde você anda na Web, mesmo quando você está navegando páginas fora desses serviços, a menos que você tome os devidos cuidados.
Existe um bocado de addons que você pode instalar no Firefox para reduzir a possibilidade tracking. (Se você usa o Chrome, é mais fácil você começar a usar o Firefox). Neste post, listo alguns deles e explico como eles podem ser usados para esse fim.
AdBlock Plus
O AdBlock Plus é um addon bem conhecido cujo uso primário é bloquear propagandas. Por si só, isso já é um começo, pois evita que os servidores de propaganda possam trackeá-lo. Porém, o AdBlock pode ser usado para bloquear quaisquer itens indesejáveis de terceiros em páginas. Por exemplo, suponha que você deseja bloquear acessos de outras páginas para o Facebook (há maneiras mais convenientes de atingir esse objetivo, todavia):
- Vá a alguma página que faça acesso ao Facebook.
- Clique no ícone do AdBlock e selecione Open blockable items (ou Abrir itens bloqueáveis).
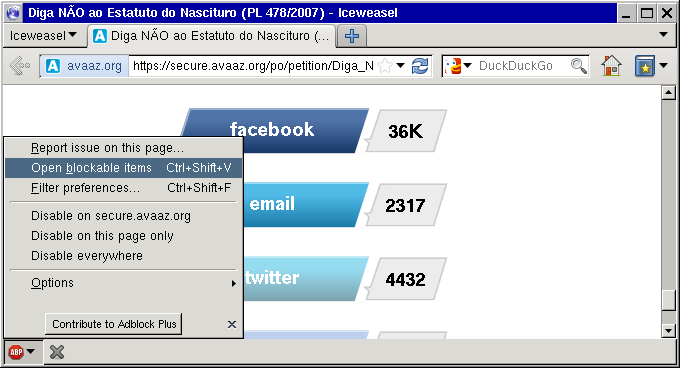
- Encontre algum dos acessos ao Facebook na lista e dê dois cliques sobre o mesmo.
- A janela que se abre apresentará várias possibilidades de regras de bloqueio. Selecione a mais apropriada (neste caso, facebook.net^; note que posteriormente você também deverá repetir o processo para o facebook.com).
- Clique no botão Advanced (ou Avançado). Este botão apresentará algumas opções adicionais à direita. Dentre elas, a mais útil é a Third-party only (ou Apenas terceiros); se marcada, essa opção impede o acesso ao facebook.net, exceto a partir do próprio facebook.net. Você pode achar isso útil se por algum diabo você ainda usa a rede social da NSA para se comunicar.
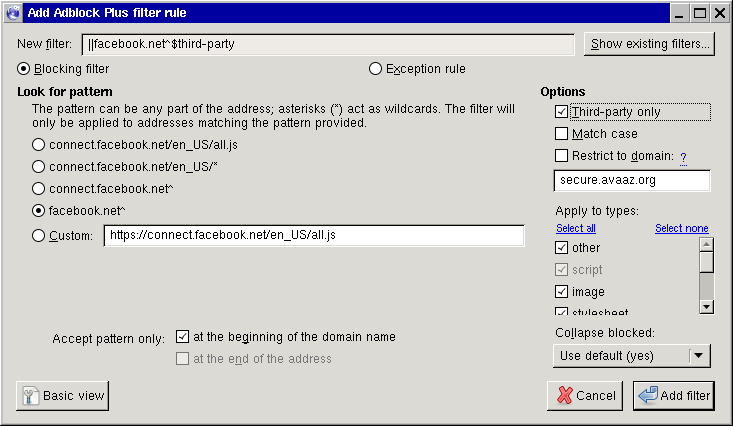
- Clique em Add filter (ou Adicionar filtro). Está feito!
Você pode bloquear outros sites (como facebook.com, twitter.com, google-analytics.com, scorecardresearch.com, etc.) da mesma maneira.
Por padrão, o AdBlock permite "ads não-intrusivos". Embora a idéia seja bem-intencionada, na prática isso significa que ele não bloqueia o Google por padrão, então é uma boa idéia desabilitar essa opção indo no menu do AdBlock, Filter preferences, primeira aba (Filter subscriptions), e desmarcar Allow some non-intrusive advertising.
Por padrão, o AdBlock faz atualizações automáticas da lista de sites a bloquear. Se você quiser evitar isso, abra o about:config, procure a opção extensions.adblockplus.subscriptions_autoupdate e dê dois cliques sobre ela para ajustá-la para false.
Disconnect
O Disconnect é um addon que já vem com uma lista padrão de sites de tracking conhecidos e bloqueia acessos aos mesmos a partir de sites de terceiros. Só descobri esse addon hoje, e como eu já uso o RequestPolicy, não cheguei a experimentá-lo direito, mas aparentemente ele funciona bem.
Smart Referer
Por padrão, sempre que o browser faz acesso a uma página a partir de outra (e.g., quando você clica em um link, ou quando uma página inclui uma imagem ou script de outra), o browser envia na requisição um header Referer, que diz qual é a proveniência do acesso (i.e., a página que continha o link ou a imagem ou script). O Smart Referer é um addon que faz com que o browser só envie esse header se a origem e o destino estiverem no mesmo domínio, o que impede o site de saber de onde você está vindo.
Já mencionei o Smart Referer antes por aqui, mas até recentemente não tinha me dado conta de quão importante ele é: uma quantidade enorme de sites usa serviços hospedados nos servidores do Google (jQuery, reCAPTCHA, Maps, entre outros), e por padrão, ao acessar esses serviços, o browser acaba informando ao Google pelo header Referer que página você está acessando. Com o Smart Referer, você evita enviar essa informação (a menos que o jQuery ou outro serviço se dê ao trabalho de enviar essa informação; pelo menos no caso do jQuery esse não parece ser o caso (ainda)).
O Smart Referer não exige configuração nenhuma, não adiciona ícone de toolbar nenhum, e faz o seu serviço quietinho sem incomodar ninguém.
HTTPS Everywhere
O HTTPS Everywhere é um addon mantido pela Electronic Frontier Foundation que traduz URLs HTTP de sites conhecidos para URLs HTTPS seguras. Por exemplo, toda vez que você acessa http://en.wikipedia.org, o addon substitui automaticamente a URL por https://en.wikipedia.org. Com isso, evita-se enviar informações não-encriptadas pela Web por descuido.
RequestPolicy
Um plugin que você pode achar útil é o RequestPolicy. Ele bloqueia todos os acessos de páginas a sites de terceiros por padrão (com exceção de uma pequena lista de acessos conhecidos, como por exemplo de wordpress.com para wp.com, e que você pode escolher na instalação), e permite adicionar exceções para sites individuais através de um ícone na barra de toolbars. O RequestPolicy é um dos plugins que melhor garante sua privacidade, às custas da inconveniência de ter que freqüentemente adicionar novas exceções para conseguir usar páginas. Ele também é útil para carregar páginas mais rápido em um 3G ou algum outro tipo de conexão lenta. Não recomendo muito para pessoas menos-que-paranóicas e que não vivam com uma conexão de 6kB/s, desde que você use alguma alternativa como o Disconnect.
Últimas observações
Uma lista de outros addons e serviços para assegurar melhor sua privacidade pode ser encontrada no PRISM Break.
Fugindo do assunto de addons, uma alternativa de serviço de e-mail para quem quer fugir do GMail é o SAPO, um provedor português. O SAPO Mail fornece 10GB de espaço e fica hospedado em Portugal, onde existe uma legislação decente de prote(c)ção de dados pessoais (dê uma olhada na política de privacidade dos camaradas).
Pidgin Off-the-Record
2013-06-07 21:33 -0300. Tags: comp, web, privacy, em-portugues
Acabei de descobrir um plugin chamado pidgin-otr (pacote pidgin-otr no Debian/Ubuntu), que permite realizar conversas encriptadas independentemente do protocolo de comunicação utilizado. O plugin funciona cifrando e decifrando mensagens individuais nos clientes, e transmitindo para o servidor o conteúdo cifrado como se fosse uma mensagem comum.
O plugin é bastante conveniente de usar. Para ativá-lo, basta instalar o pacote e habilitá-lo na janela de plugins do Pidgin (Tools > Plugins > Off-the-Record Messaging). A partir daí, as janelas de conversação apresentarão um ícone que permite iniciar uma conversa privada (desde que o outro usuário também possua o plugin). Pelo que eu entendi, uma vez que isso tenha sido feito para um usuário, conversas posteriores serão cifradas automaticamente por padrão.
Quem me contou foi o Reddit (em um post sobre a acesso da NSA a dados do Google, Apple, Facebook e diversas outras organizações estadunidenses).
To tweet or not to tweet
2013-04-07 22:41 -0300. Tags: life, comp, web, privacy, em-portugues
Dracula: "I'm all screwed"
Richter: "I am the instrument of your doom"
Dracula: "Perhaps not... not yet"
Richter: "What!?!?!"
???: "Richter! You killed my father! Prepare to die!"
Richter: "ALUCARD!!!"
Alucard: "You can't know... you'll never know how it feels..."
* TUM *
Richter: "NOOOOOOOO!"
– Castlevania, Hélio's edition
Há pouco mais de um ano eu abandonei o Twitter (well, not quite; eu só parei de postar lá, na verdade) por conta de eles terem vendido o acesso à base de tweets para umas empresinhas de mineração de dados. Há pelo menos metade desse tempo eu venho remoendo essa decisão.
Assumptions
Na época eu usava o Twitter com "tweets protegidos", i.e., apenas as pessoas que eu autorizei que me seguissem podiam ver os meus tweets. Eu assumia assim que apenas uns poucos conhecidos veriam o que eu estava postando.
Não é bem assim que a coisa funciona. Embora tweets protegidos não sejam retweetáveis, nada impede alguém capaz de ler um tweet de copiá-lo e retweetá-lo na mão. Retweets são uma feature fundamental do Twitter; não faz muito sentido contar com que algo postado no Twitter não vá ser retweetado. Proteger os tweets não melhora muito a situação.
Abandonemos, pois, a noção de que existe "publicidade seletiva" no Twitter: assumamos que "o que você diz no Twitter pode ser visto no mundo inteiro instantaneamente" (palavras dos termos de serviço, as it happens). E por "o mundo inteiro", leia-se o mundo inteiro. Na época da matrícula da UFRGS nesse ano eu vi alguns retweets da @ufrgsnoticias que provavelmente não estavam nos planos dos indivíduos retweetados e que eu fiquei cogitando comigo mesmo se não poderiam causar algum problema para os mesmos. Essa "falta de privacidade" é, me parece, uma propriedade fundamental do serviço Twitter, não um erro da companhia Twitter que o fornece. Assim (me parece), não faz sentido condenar o Twitter por esse tipo particular de falta de privacidade, mas tão-somente aprová-la ou não (e utilizar ou não o serviço de acordo).
(Essa falta de privacidade na verdade é uma propriedade compartilhada com blogs e páginas pessoais. No Twitter isso é um pouco mais acentuado pela facilidade de retweetar posts alheios, mas não é fantasticamente diferente. Essa "publicidade fundamental" é diferente do vazamento de informações pessoais para terceiros que não é fundamental para o serviço e não é do interesse do usuário. Mais sobre isso adiante.)
Ok, tweets são públicos. "Tweet privado" é praticamente uma contradição em termos. Aceitemos esse fato e tomemos por princípio que o Twitter só serve para postar coisas que não nos importamos de compartilhar com o mundo (e.g., links para coisas interessantes, recomendações de filmes/livros, etc.). Entendido isto, podemos seguir usando o Twitter com a consciência limpa.
Heh, não
Faltam dois problemas a considerar. O primeiro é o uso que se faz dessa informação além da mera publicação mundial. Isso inclui a venda ao acesso da base de tweets para as empresinhas de data mining, que foi a causa original do meu desgosto pelo Twitter.
Na verdade, o Twitter sempre vendeu o acesso a tweets, mesmo antes desse incidente; a diferença é apenas que o Twitter costumava limitar o acesso aos tweets dos últimos trinta dias. (O fato de que eles já brincavam de vender tweets antes não torna o ato de vender o acesso à base inteira nem mais nem menos ético, mas vamos adiante.)
O segundo problema são as outras informações que caem nas mãos do Twitter além dos tweets, e que uso o Twitter faz delas. Vamos por partes.
A miserable little pile of non-secrets
Pois, o Twitter vende, e sempre vendeu, o acesso a (porções da) base de tweets. Esses tweets são públicos para início de conversa*. A diferença entre baixá-los você mesmo e comprar o acesso é que as APIs do Twitter impõem certos limites na busca de tweets (e.g., aparentemente existe um limite de 1500 tweets nos resultados de buscas por termos), e que provavelmente a base é oferecida em um formato mais conveniente de manipular. (* Tweets protegidos são outra história. Eles vivem em um limbo questionável: a política de privacidade jamais menciona "tweets protegidos", então pelo menos para mim não está claro se eles são considerados informação pública (e conseqüentemente comercializável), ou se estão inclusos entre os dados pessoais que o Twitter diz não vender (o que não impede que o Twitter seja comprado e com ele seus dados, but I digress).)
A possibilidade de data mining, assim, pode aumentar com o fato de que o acesso à base de tweets é comercializado, mas ela não deixa de existir sem essa comercialização. Na verdade, a Internet inteira é alvo de data mining. Google (a organização) e outros mecanismos de busca já podem facilmente explorar toda informação pública na Internet, independentemente do seu consentimento. A diferença de postar no Twitter é facilitar a vida do Twitter e parceiros, mas postar em qualquer outro local público da web (como o identi.ca, ou seu blog pessoal) tem o mesmo risco.
É uma propriedade da Internet que toda informação pública é (em geral) facilmente acessível. Uma conseqüência disso é que coisas que antes eram muito difíceis (e.g., catar todas as notícias sobre um certo tópico ou pessoa nos jornais dos últimos N anos) agora são viáveis, e, junto com todas as vantagens que isso proporciona, vêm certas conseqüências negativas para a privacidade das pessoas. A sociedade vai ter que dar um jeito de se adaptar a isso, mas não é um problema do qual se possa escapar trocando o serviço em que essas informações serão publicadas (assumindo que se pretenda publicar essas informações para quem quer que as queira ler).
Fica a questão de se é ok o Twitter ganhar dinheiros vendendo acesso aos meus posts sem me pagar nada. Essa questão é sugerida como um exercício para o leitor.
The actual secrets
O segundo problema são os outros dados além dos tweets. Esses dados podem ser divididos em duas classes: os dados "inevitáveis", i.e., aqueles que o Twitter necessariamente obtém a partir do uso do serviço; e os dados "evitáveis", i.e., aqueles que você pode evitar mandar com um pouco de cuidado.
Os dados inevitáveis incluem:
- Seu IP e horários de acesso. Isso não é uma particularidade do Twitter, e sim um problema de todo serviço Web. Esses dados são particularmente preocupantes se o serviço é acessado periodicamente, já que em tese eles permitem determinar onde você esteve em dados momentos (e.g., se você acessa o serviço por celular e o seu IP varia dependendo do lugar onde você está).
Pode parecer (e me parece) improvável que o Twitter esteja interessado nessa informação. Porém, vale lembrar que o Twitter se localiza nos Estados Unidos, e portanto esses dados podem ser solicitados pelo governo daquele país, coisa da qual você pode não gostar. Na verdade, entretanto, seu IP e horários de acesso são um dado visível por todos os roteadores entre você e o serviço, o que significa que eles estão disponíveis para muita gente. Como já mencionado, isso é um problema da infraestrutura da Internet existente. Uma solução seria usar algo como o Tor na Internet inteira, mas isso é assunto para outra discussão.
Um ponto é que esses dados são inevitavelmente mandados para o Twitter. O outro é o que o Twitter faz com eles. Segundo a política de privacidade, "Log Data" é mantida por 18 meses, e depois disso pode ser ou removida ou simplesmente "desidentificada" (o que pode não ser suficiente).
- Sua lista de seguidores e seguidos. Em parte, esse é o tipo de dado que faz de uma rede social o que ela é. That's a bug and a feature. Além das listas, é possível determinar com quais pessoas você se comunica mais através dos seus tweets.
Os dados evitáveis incluem:
- Por onde você esteve. Diversos sites possuem "widgets" que permitem compartilhar a página via Twitter (entre outras redes sociais). Esses widgets são escritos de tal maneira que o Twitter fica sabendo que você acessou a página. A princípio, "Widget Data" começa a ser "apagada ou agregada" até 10 dias após sua coleta.
Essa informação é usada, entre outras coisas, para sugerir pessoas a seguir baseado nas páginas que você visitou, desde que você tenha optado por ativar essa feature. Se você estiver com o Do Not Track ativado, o Twitter pára de coletar dados no que diz respeito a essa feature. Eles não deixam de receber os dados, e não deixam de mantê-los por dez dias, pelo que eu entendo. Além disso, nem os termos de serviço nem a política de privacidade fazem qualquer menção ao Do Not Track, como comentado no post linkado anteriormente; apenas as páginas de ajuda falam sobre o assunto.
De qualquer forma, você pode evitar mandar essa informação simplesmente bloqueando acesso de sites de terceiros ao Twitter. No Firefox, você pode usar o AdBlock Plus para isso; a maneira mais fácil é acessar qualquer página que contenha um widget do Twitter, clicar no ícone do AdBlock, selecionar "Open blockable items", achar o platform.twitter.com e dar dois cliques sobre o cidadão. Na janela que se abre, clique no botão "Advanced view", e selecione a opção "Third-party only" (i.e., o Twitter só deve ser bloqueado a partir de sites de terceiros). Uma solução mais drástica é usar o RequestPolicy, que bloqueia tudo por padrão, mas pode ser um tanto quanto inconveniente de usar.
- Para onde você vai. Links externos em tweets são "reduzidos" para uma URL do tipo http://t.co/..., mesmo que a URL "reduzida" não seja menor que a original, e mesmo que a redução não seja necessária para o tweet caber em 140 caracteres. O Twitter faz isso para poder trackear para onde você está indo.
Interessantemente, quando você pára o mouse sobre um link desse tipo, a URL original aparece como title-text (i.e., em um popup), ou diretamente como o texto do link se for suficientemente curta. Assim, você pode usar o Greasemonkey e criar um novo user script com este conteúdo para fazer com que o Firefox substitua os links t.co pelos links originais na página do Twitter.
Fica a questão de se é "certo" usar um serviço que coleta dados que você acha que ele não deveria coletar só porque você consegue burlar a coleta. A resposta depende de quão idealista você está se sentindo hoje.
Outros comentários
Uma desvantagem de usar um serviço centralizado para publicação de informações (e.g., Twitter, Blogger, Wordpress, Facebook (ok, o Facebook tem inúmeros outros problemas, but I digress)) é que os "dados inevitáveis", tais como logs de acesso, ficam concentrados com uma única organização. Mesmo na arquitetura atual da Internet, em que acessar um serviço implica contar-lhe onde você está e possivelmente outros dados, a situação não é tão ruim se os dados estão espalhados entre vários servidores, o que dificulta sua exploração. (Seu provedor de acesso continua com um bocado de informação, entretanto.)
Por outro lado, uma rede social é mais útil quando um grande número de pessoas a usa; essa é uma vantagem de "todo o mundo" usar o Twitter, ao invés de cada um "roll their own" microblog. Porém, em teoria nada impede que cada um rolle seu own microblog e todos funcionem de maneira integrada, desde que eles usem um protocolo comum de comunicação.
µ.
Conclusão
A conclusão é que talvez eu volte a usar o Twitter no futuro próximo. Ou não.
Facebook stalks you
2012-01-05 23:49 -0200. Tags: comp, web, privacy, em-portugues
Que o Facebook não tem respeito nenhum pela privacidade dos seus usuários não é nenhuma novidade. Porém, os meios de que ele se utiliza para obter dados ainda me surpreendem.
Como bom nerd, eu tenho o costume de olhar os logs de acesso do blog para ver em que páginas as pessoas têm caído. Ontem eu notei uma seqüência de acessos interessante:
Data: 2013-01-04 01:50:01 -0200
IP: (removido)
URL: /~vbuaraujo/blog/?entry=20120820-xmodmap
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.97 Safari/537.11
Referer: http://www.facebook.com/l.php?u=http%3A%2F%2Finf.ufrgs.br%2F~vbuaraujo%2Fblog%2F%3Fentry%3D20120820-xmodmap&h=VAQEHMeNj
Data: 2013-01-04 01:50:01 -0200
IP: 66.220.158.114
URL: /~vbuaraujo/blog/?entry=20120820-xmodmap
User-Agent: facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
Referer: (vazio)
Isto é:
- Usuário abre um link via Facebook;
- Logo depois o Facebook requisita a página para olhar.
O link contido na string de User-Agent do bot do Facebook tem o seguinte a dizer:
Why does Facebook appear in my server logs?
Facebook allows its users to send links to interesting web content to other Facebook users. Part of how this works on the Facebook system involves the temporary display of certain images or details related to the web content, such as the title of the webpage or the embed tag of a video. Our system retrieves this information only after a user provides us with a link. You may have found this page because a Facebook user sent a link from your website to other Facebook users. If you have any questions or concerns about any links or content sent by one of our users, please contact us at legal@facebook.com.
Parece útil, não? Parece quase uma razão legítima para stalkear o usuário (heh). Acontece, entretanto, que os acessos do facebookexternalhit normalmente ocorrem menos de um segundo depois que um usuário clica em um link, não quando o link é submetido. Não tenho conta no Facebook, e portanto não tenho como testar melhor isso; estou me guiando pelos acessos do facebookexternalhit nos logs. (Para minha surpresa, o bot já tinha visitado o blog algumas vezes antes. Nunca tinha descoberto porque os acessos foram ao famoso post sobre os horários dos TM{1,2,3}, que eu filtro dos logs para visualizar, já que ele é responsável pela grande maioria dos acessos.) Porém, nem sempre os dois acessos aparecem juntos, então não sei exatamente qual é o princípio por trás disso.
Da impossibilidade de se dizer tudo o que pensa
2012-07-22 03:39 -0300. Tags: about, privacy, life, em-portugues
Ocasionalmente certa pessoa vem me reclamar que eu tenho postado poucos posts não-técnicos. Como eu já comentei anteriormente, a tendência é isso continuar assim. Explico-me. O fato é que o blog hoje em dia recebe muito mais acessos do que no começo. Devido a algum fenômeno sobrenatural, provavelmente relacionado com o fato de ele estar hospedado debaixo do ufrgs.br, o blog tem um peso preocupantemente alto para o camarada Google. Para dar uma idéia, dois dias depois de eu escrever o post sobre o Busybox no Android já tinha gente caindo nele via Google procurando por informações de como instalar o Busybox e o Dropbear no Android. O ponto é que o blog tem uma visibilidade grande, e se por um lado isso é positivo (eu me sinto mais motivado a escrever os posts técnicos sabendo que eles poderão ser de fato úteis a quem possa estar procurando a informação), por outro lado isso significa que eu tenho que ter mais cuidado com o que eu posto por aqui (e certas experiências recentes serviram para me lembrar disso). Tudo o que nós dizemos nessa tal de Internet, seja em um blog, seja na sua rede social favorita, poderá ser usado contra você no tribunal. Isso inclui sua vida profissional e acadêmica. Isso também inclui familiares e conhecidos, e esse para mim é o ponto mais incômodo, na verdade. Já experimentou manter um diário? Você normalmente toma precauções para que ele não caia em mãos erradas. Pois bem, disponibilizá-lo via HTTP não vai contribuir para esse objetivo.
A conclusão disso tudo é que posts técnicos continuarão sendo a maioria. Pretendo continuar postando coisas não-técnicas por aqui, mas como a filtragem sobre elas de uns tempos para cá é maior, pode-se esperar uma freqüência menor delas. Também quero ver se posto mais coisas sobre lingüística por aqui.
Enfim. Com este, temos três post sobre o blog na front page do blog*. Vamos parar com esse negócio.
[* Embora o foco deste aqui não seja exatamente o blog, e sim a impossibilidade de se dizer tudo o que pensa. Whatever.]
[Edit: Isso aqui foi um midnight rant. Eu não sei com que freqüência eu vou postar qualquer coisa por aqui. Cansei de me explicar. Blargh.]
Communications with the Twitter Team
2012-05-30 21:43 -0300. Tags: comp, web, privacy, em-portugues
Formatação HTML e links adicionados por conveniência.
From: Vítor De Araújo <µµµ@µµµ.com>
To: privacy@twitter.com
Subject: Questions about Do-Not-Track and protected tweets
Date: Fri, 25 May 2012 15:00:28 -0300Hi!
I have two points I'd like to question about Twitter's privacy policy.
- Recently Twitter announced that it now honors the Do-Not-Track header. I have also noticed that you have updated the privacy policy, but I don't see any mention of Do-Not-Track in the text. So, does the commitment to Do-Not-Track have any official value, i.e., is it something users can rely on as long as the current privacy policy is in effect, and if so, what guarantees that?
- The policy does not directly say anything about protected tweets. May Twitter share protected tweets with third parties according to the current policy? Also, I noticed that the current policy states that information about who I follow and who follows me can be shared, something the old policy didn't. May this information be shared even for protected accounts?
I left Twitter in late February when I came to know about the selling of the historical tweet database to DataSift. I liked Twitter a lot, and I would be more confortable using it if the policy gave explicit guarantees about protected posts and accounts not being shared.
Thanks for the attention!
Five days later...
From: phantasm <notifications-support@twitter.zendesk.com>
To: Vítor De Araújo <µµµ@µµµ.com>
Subject: #5352694 Twitter Support: update on "Questions about Do-Not-Track and protected tweets"
Date: Wed, 30 May 2012 16:55:36 +0000#5352694 Twitter Support: update on "Questions about Do-Not-Track and protected tweets"
----------------------------------------------
phantasm, May 30 09:55 am (PDT):Hi,
Thanks for your inquiry. Our Privacy Policy at http://twitter.com/privacy describes the information that Twitter receives, the purposes for which it may be used, and the limited circumstances in which private personal information may be shared.
Regards,
The Trust & Safety Team
I had hope.
Google dies, Twitter dies, the self must also die
2012-03-01 20:44 -0300. Tags: comp, web, privacy, em-portugues
"Die, Twitter! You don't belong in this world."
"It was not by my hands that I'm once again given cash. I was brought here by humans, who want to pay me tribute."
"Tribute? You steal men's tweets, and sell them to your knaves."
"Perhaps the same could be said of all social networks."
"Your words are as empty as your privacy policy. Mankind ill needs a network such as you."
"What is a profile? A miserable little pile of secrets? But that's enough talk. Have at you!"
— Twittlevania: Symphony of the Night
Há mais ou menos um mês o Google anunciou que mudaria sua política de privacidade. A nova política entrou em vigor hoje, e permite ao Google cruzar os dados de seus diversos serviços para melhor servi-lo. Acho mui nobre e respeitável eles terem avisado enfaticamente com um mês de antecedência das mudanças. Mas respeitável ou não, eu já estava há horas com vontade de abandonar o Google, e esse foi o último empurrãozinho que me faltava. Nunca usei o GMail, pela questão da privacidade, então não tinha muito a perder. Matei minha Google Account no final do dia 28 de fevereiro (afinal, eles não explicitaram a partir de 1º de março de qual fuso-horário a política nova entra em vigor).
Na iminência de perder o orkut, e na necessidade de suprir minha compulsão de compartilhar links que ninguém lê, resolvi criar uma conta no Twitter no final de janeiro. Depois de observar alguns bots dando "follow" no meu perfil, e depois de me dar conta de como é fácil fazer data mining no Twitter (ainda mais com as APIs que o Twitter fornece), protegi minha conta.
Estava muito feliz com o Twitter.
Ontem o Twitter vendeu o acesso a todos os tweets postados desde 2010 para duas empresas de pesquisa. A empresa britânica de data mining Datasift fornecerá acesso aos dados através de uma plataforma cloud-based, que dá acesso não apenas ao conteúdo dos tweets, mas também a dados computados a partir dos mesmos. "We enrich every Tweet, every social conversation with sentiment, social media influence, topic-analysis, and NLP. No-one offers more insights for Tweets."
A empresa alega que conversas privadas (para algum valor de "privado"; nada garante que a definição inclui tweets protegidos) e tweets excluídos não serão acessíveis pelo sistema (o que não quer dizer que a empresa não tenha acesso aos mesmos), mas não podemos ter certeza de nada. De fato, os termos de serviço e a política de privacidade do Twitter não dão qualquer garantia quanto à privacidade de tweets protegidos. Tudo o que elas dizem é que "What you say on Twitter may be viewed all around the world instantly. You are what you Tweet!".
Por essa razão, estou em vias de matar minha conta no Twitter. Se todos fizessem o mesmo com serviços que desrespeitam nossa privacidade, as empresas seriam obrigadas a respeitá-la, para não perder o lucro. Infelizmente, o mundo tende a preferir conveniência a privacidade. Um dia o mundo aprende. Ou não.
Addons para combater tracking
2012-02-26 21:01 -0300. Tags: comp, web, privacy, em-portugues
O artigo sobre o uso do User-Agent para tracking me levou por um passeio seguindo os links de artigos relacionados pelo site da EFF. Recomendo que você faça o mesmo. Resolvi experimentar alguns dos addons recomendados neste artigo, além de alguns outros addons relacionados que encontrei pelo caminho. São eles:
- NoScript, um addon que bloqueia JavaScript por padrão e permite ativá-lo seletivamente para alguns sites de maneira simples;
- RequestPolicy, um addon similar para bloquear requests de um domínio para outro;
- Cookie Monster, similar para ativação seletiva de cookies;
- Smart Referer, que envia o header Referer apenas quando a origem e o destino do link estão no mesmo domínio.
Com exceção do último, todos esses addons estão nos repositórios do Debian/Ubuntu, de modo que para instalá-los basta um comando: apt-get install xul-ext-cookie-monster xul-ext-noscript xul-ext-requestpolicy. Depois disso, basta reiniciar o Firefox. O outro addon pode ser baixado do site da Mozilla.
No início, usar esses plugins é um pouco inconveniente: deve-se liberar cada site confiável que se visita da primeira vez. Porém, isso é um termo constante e não afeta a complexidade assintótica da navegação (ou quase). (Por outro lado, o Smart Referer é totalmente invisível e não afeta em nada a navegação, portanto não há desculpas para não usá-lo.)
Outro inconveniente que encontrei é que o RequestPolicy pede confirmação para redirecionamentos de páginas, que em geral são inofensivos [citation needed], e não há uma opção para liberar redirecionamentos para todos os sites por padrão.
Como ponto positivo, se carrega menos porcarias ao acessar uma página, o que pode ter um efeito significativo quando se está usando um 3G da vida. (Além do benefício à privacidade, obviamente.)
No más.