Posts com a tag: web
On the Twitter shitshow
2022-12-18 19:49 +0000. Tags: comp, web, in-english
The day after Elon Musk finalized the acquisition of Twitter, I decided to stop using it and move definitively to Mastodon. I thought things would go downhill at Twitter, but honestly, I did not think they would go downhill so fast. Since then:
Musk fired half of the Twitter staff, and then tried to hire some of the people back after realizing he actually needed some of them.
We had the whole Twitter Blue fiasco, where the Twitter ‘verified’ checkmark, previously available only to public figures by verifying your identity with the Twitter staff, could now be obtained by anyone by buying a Twitter Blue subscription, with much hilarity ensuing.
Musk banned some accounts tracking the locations of billionaires’ private jets (obtained from publicly available information). Subsequently, he also banned a number of journalists that had published articles about the aforementioned ban. He also banned the Mastodon project’s account on Twitter, supposedly because it posted a tweet saying that some of the jet tracking accounts had moved to Mastodon.
The journalists’ and Mastodon’s accounts have been reinstated, but since then, Twitter has been blocking links to
mastodon.social(and many other instances). Attempts to tweet links to it yield an error with no explanation to the user: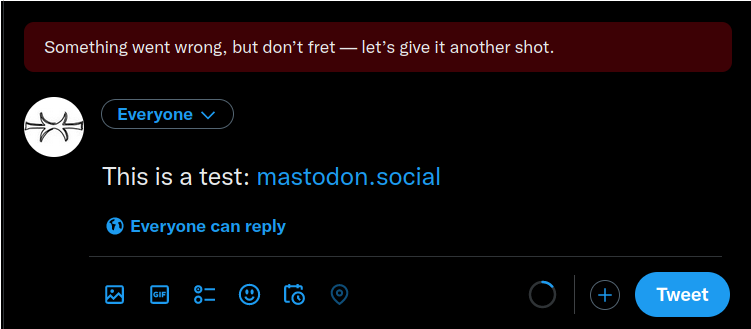
And attempts to follow an existing link yield to a page saying that the link ‘may be unsafe’:
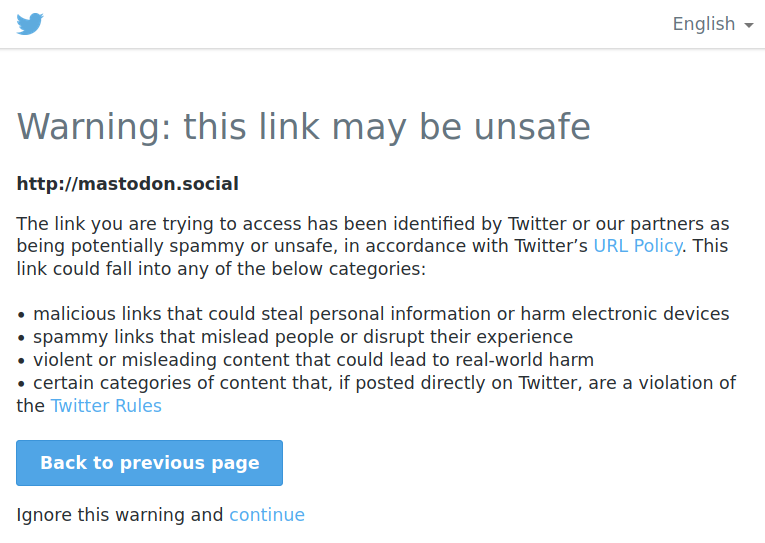
While writing this post, I found out that “promotion of alternative social platforms”, such as linking to your account on Mastodon, Instagram or Facebook, is now forbidden by Twitter policy. [Update (2022-12-19): That page has been deleted. You can see the WebArchive version.]
The banning of journalists for talking about things Elon does not like, and blocking of Mastodon links, should be a clear enough sign that (1) Twitter is entirely under the whims of its new owner, and (2) the guy has whims aplenty. This is not anymore a situation of “I will stop using this service because it will likely become crap in the future”, it’s a situation of “I cannot use this service anymore because it’s crap already”. If they follow through with their new policy, my account there (which currently only exists to point to my Mastodon one, and to keep the username from being taken) will soon probably be suspended through no effort of my own.
All of this is quite disturbing considering the reliance of journalists on Twitter. Mastodon is a nice place if your goal is to find people with common interests and have conversations with them, but for journalists, I think the main value of Twitter is finding out news about what is happening in the world, through trending topics, global search, and things going viral, none of which are things Mastodon is designed to provide or encourage (on the contrary, Mastodon is in many ways designed to avoid such features). Therefore, I don’t see journalists migrating en masse to Mastodon. However, begging the billionaire to not expel them from his playground is not a sustainable course of action in the long run (and even in the short run, judging by the speed of things so far). I’m curious about how things will roll out on that front.
Given all that, I won’t be posting to Twitter anymore, not even to announce new blog posts as I used to do. You can follow this blog via RSS feed as always, or follow me on Mastodon at @elmord@functional.cafe. (Maybe one day I will add an option to subscribe by e-mail, but that will require setting up an e-mail server, and so far I have not found the will to do that. And yes, it’s been almost a year since I last posted anything here, but this blog is not quite dead.)
Some thoughts on Gemini and the modern Web
2022-02-20 19:22 +0000. Tags: comp, web, ramble, in-english
The web! The web is too much.
Gemini is a lightweight protocol for hypertext navigation. According to its homepage:
Gemini is a new internet protocol which:
- Is heavier than gopher
- Is lighter than the web
- Will not replace either
- Strives for maximum power to weight ratio
- Takes user privacy very seriously
If you’re not familiar with Gopher, a very rough approximation would be navigating the Web using a text-mode browser such as lynx or w3m. A closer approximation would be GNU Info pages (either via the info utility or from within Emacs), or the Vim documentation: plain-text files with very light formatting, interspersed with lists of links to other files. Gemini is essentially that, except the files are remote.
Gemini is not much more than that. According to the project FAQ, “Gemini is a ‘less is more’ reaction against web browsers and servers becoming too complicated and too powerful.” It uses a dead-simple markup language called Gemtext that is much simpler than Markdown. It has no styling or fancy formatting, no client-side scripting, no cookies or anything that could be used for tracking clients. It is designed to be deliberately hard to extend in the future, to avoid such features from ever being introduced. For an enthusiastic overview of what it is about, you can check this summary by Drew DeVault.
I’m not that enthusiastic about it, but I can definitely see the appeal. I sometimes use w3m-mode in Emacs, and it can be a soothing experience to navigate web pages without all the clutter and distraction that usually comes with it. This is big enough of an issue that the major browsers implement a “reader mode” which attempt to eliminate all the clutter that accompanies your typical webpage. But reader mode does not work for all webpages, and won’t protect you from the ubiquitous surveillance that is the modern web.
I do most of my browsing on Firefox with uBlock Origin and NoScript on. Whenever I end up using a browser without those addons (e.g., because it’s a fresh installation, or because I’m using someone else’s computer), I’m horrified by the experience. uBlock is pretty much mandatory to be able to browse the web comfortably. Every once in a while I disable NoScript because I get tired of websites breaking and having to enable each JavaScript domain manually; I usually regret it within five minutes. I have a GreaseMonkey script to remove fixed navbars that websites insist on adding. Overall, the web as it exists today is quite user-inimical; addons like uBlock and NoScript are tools to make it behave a little more in your favor rather than against you. Even text-mode browsers like w3m send cookies and the Referer header by default, although you can configure it not to. Rather than finding and blocking each attack vector, a different approach would be to design a platform where such behaviors are not even possible. Gemini is such a platform.
The modern web is also a nightmare from an implementor side. The sheer size of modern web standards (which keep growing every year) mean that it’s pretty much out of question for a single person or a small team to write and maintain a new browser engine supporting modern standards from scratch. It would take years to do so, and by that time the standards would have already grown. This has practical consequences for users: it means the existing players face less competition. Consider that even Microsoft has given up on maintaining its own browser engine, basing modern versions of Edge on Chromium instead. Currently, three browser engines cover almost all of the browser market share: Blink (used by Chrome, Edge and others); WebKit (used by Safari, and keeping a reasonable portion of the market by virtue of being the only browser engine allowed by Apple in the iOS app store); and Gecko (used by Firefox, and the only one here that can claim to be a community-oriented project). All of these are open-source, but in practice forking any of them and keeping the fork up-to-date is a huge task, especially if you are forking because you don’t like the direction the mainstream project is going, so divergencies will accumulate. This has consequences, in that the biggest players can push the web in whatever direction they see fit. The case of Chrome is particularly problematic because it is maintained by Google, a company whose main source of revenue comes from targeted ads, and therefore has a vested interest in making surveillance possible; for instance, whereas Firefox and Safari have moved to blocking third-party cookies by default, Chrome doesn’t, and Google is researching alternatives to third-party cookies that still allow getting information about users (first with FLoC, now with Topics), whereas what users want is not to be tracked at all. The more the browser market share is concentrated in the hands of a few players, the more leeway those players have in pushing whatever their interests are at the expense of users. By contrast, Gemini is so simple one could write a simplistic but feature-complete browser for it in a couple of days.
Gemini is also appealing from the perspective of someone authoring a personal website. The format is so simple that there is not much ceremony in creating a new page; you can just open up a text editor and start writing text. There is no real need for a content management system or a static page generator if you don’t want to use one. Of course you can also keep static HTML pages manually, but there is still some ceremony in writing some HTML boilerplate, prefixing your paragraphs with <p> and so on. If you want your HTML pages to be readable in mobile clients, you also need to add at least the viewport meta tag so your page does not render in microscopic size. There is also an implicit expectation that a webpage should look ‘fancy’ and that you should add at least some styling to pages. In Gemini, there isn’t much style that can be controlled by authors, so you can focus on writing the content instead. This may sound limiting, but consider that most people nowadays write up their stuff in social media platforms that also don’t give users the possibility of fancy formatting, but rather handle the styling and presentation for them.
* * *
As much as I like this idea of a bare-bones, back-to-the-basics web, there is one piece of the (not so) modern Web that I miss in Gemini: the form. Now that may seem unexpected considering I have just extolled Gemini’s simplicity, and forms deviate quite a bit from the “bunch of simple hyperlinked text pages” paradigm. But forms do something quite interesting: they enable the Web to be read-write. Project such as collaborative wikis, forums, or blogs with comment sections require some way of allowing users to send data (other than just URLs) to the server, and forms are a quite convenient and flexible way to do that. Gemini does have a limited form of interactivity: the server may respond to a request with an “INPUT” response code which tells the user browser to prompt for a line of input, and then repeat the request with the user input appended as the query string in the URL (sort of like a HTTP GET request). This is meant to allow implementing pages such as search engines which prompt for a query to search, but you can only ask for a single line of input at a time this way, which feels like a quite arbitrary limitation. Forms allow an arbitrary number of fields to be inputted, and even arbitrary text via the <textarea> element, making them much more general-purpose.
Of course, this goes against the goal stated in the Gemini FAQ that “A basic but usable (not ultra-spartan) client should fit comfortably within 50 or so lines of code in a modern high-level language. Certainly not more than 100.” It also may open a can of worms, in that once you want to have forums, wikis or other pages that require some form of login, you will probably want some way to keep session state across pages, and then we need some form of cookies. Gemini actually already has the idea of client-side certificates which can be used for maintaining a session, so maybe that’s not really a problem.
As a side note, cookies (as in pieces of session state maintained by the client) don’t have to be bad, the web just happens to have a pretty problematic implementation of that idea, amplified by the fact that webpages can embed resources from third-party domains (such as images, iframes, scripts, etc.) that get loaded automatically when the page is loaded, and the requests to obtain those resources can carry cookies (third-party cookies). Blocking third-party cookies goes a long way to avoid this. Blocking all third-party resources from being loaded by default would be even better. Webpages would have to be designed differently to make this work, but honestly, it would probably be for the best. Alas, this ship has already sailed for the Web.
* * *
There are other interesting things I would like to comment on regarding Gemini and the Web, but this blog post has been lying around unfinished for weeks already, and I’m too tired to finish it at the moment, so that’s all for now, folks.
My terrible nginx rules for cgit
2020-08-16 12:40 +0100. Tags: comp, unix, web, in-english
I’ve been using cgit for hosting my Git repositories since about the end of 2018. One minor thing that annoys me about cgit is that the landing page for repositories is not the about page (which shows the readme), but the summary page (which shows the last commits and repository activity). This is a useful default if you are visiting the page of a project you already know (so you can see what’s new), but not so much for someone casually browsing your repos.
There were (at least) two ways I could solve this:
I could change the cgit source code to use the about page as a default. This would require figuring out all parts to change, and keeping my own patched version of cgit. Or…
I could come up with a pile of nginx rules to map the external URLs I want (e.g.,
/code/<repo-name>/) into cgit’s own URLs (e.g.,/cgit/<repo-name>/about/).
I went with the second option.
Things are not so simple, however: even if I map my external URLs into cgit’s internal ones, cgit will still generate links pointing to its own version of the URLs. So the evil masterplan is to have two root locations:
/code/, which exposes the URLs the way I want them, translates them to cgit’s URLs, and passes the translated versions to cgit;/cgit/, which redirects cgit-style URLs to the corresponding/code/URLs. This way, cgit can still generate links to its own version of the URLs, and they will get translated back to the external URLs when the user follows the links.
In the rest of this post, I will go through the nginx rules I used. You can find them here if you would like to see them all at once.
The cgit FastCGI snippet
We will need four different rules for the /code location. All of them involve passing a translated URL to cgit, which involves setting up a bunch of FastCGI variables, most of which are identical in all rules. So let’s start by creating a file in /etc/nginx/snippets/fastcgi-cgit.conf which we can reuse in all rules:
fastcgi_pass unix:/run/fcgiwrap.socket; fastcgi_param QUERY_STRING $query_string; fastcgi_param REQUEST_METHOD $request_method; fastcgi_param CONTENT_TYPE $content_type; fastcgi_param CONTENT_LENGTH $content_length; fastcgi_param REQUEST_URI $request_uri; fastcgi_param DOCUMENT_URI $document_uri; fastcgi_param SERVER_PROTOCOL $server_protocol; fastcgi_param GATEWAY_INTERFACE CGI/1.1; fastcgi_param SERVER_SOFTWARE nginx/$nginx_version; fastcgi_param REMOTE_ADDR $remote_addr; fastcgi_param REMOTE_PORT $remote_port; fastcgi_param SERVER_ADDR $server_addr; fastcgi_param SERVER_PORT $server_port; fastcgi_param SERVER_NAME $server_name; # Tell fcgiwrap about the binary we’d like to execute and cgit about # the path we’d like to access. fastcgi_param SCRIPT_FILENAME /usr/lib/cgit/cgit.cgi; fastcgi_param DOCUMENT_ROOT /usr/lib/cgit;
These are standard CGI parameters; the only thing specific to cgit here is the SCRIPT_FILENAME and DOCUMENT_ROOT variables. Change those according to where you have cgit installed in your system.
The /code/ rules
Now come the interesting rules. These go in the server { ... } nginx section for your website (likely in /etc/nginx/sites-enabled/site-name, if you are using a Debian derivative). Let’s begin by the rule for the landing page: we want /code/<repo-name>/ to map to cgit’s /<repo-name>/about/:
location ~ ^/code/([^/]+)/?$ {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /cgit;
fastcgi_param PATH_INFO $1/about/;
}
The location line matches any URL beginning with /code/, followed by one or more characters other than /, followed by an optional /. So it matches /code/foo/, but not /code/foo/bar (because foo/bar has a /, i.e., it is not “one or more characters other than /”). The foo part (i.e., the repo name) will be accessible as $1 inside the rule (because that part of the URL string is captured by the parentheses in the regex).
Inside the rule, we include the snippet we defined before, and then we set two variables: SCRIPT_NAME, which is the base URL cgit will use for its own links; and PATH_INFO, which tells cgit which page we want (i.e., the <repo-name>/about page). Note that the base URL we pass to cgit is not /code, but /cgit, so cgit will generate links to URLs like /cgit/<repo-name>/about/. This is important because later on we will define rules to redirect /cgit URLs to their corresponding /code URLs.
The second rule we want is to expose the summary page as /code/<repo-name>/summary/, which will map to cgit’s repo landing page:
location ~ ^/code/([^/]+)/summary/$ {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /cgit;
fastcgi_param PATH_INFO $1/;
}
Again, the principle is the same: we match /code/foo/summary/, extract the foo part, and pass a modified URL to cgit. In this case, we just pass foo/ without the summary, since cgit’s repo landing page is the summary.
The third rule is a catch-all rule for all the other URLs that don’t require translation:
location ~ ^/code/(.*) {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /cgit;
fastcgi_param PATH_INFO $1;
}
That is, /code/ followed by anything else not matched by the previous rules is passed as is (removing the /code/ part) to cgit.
The /cgit/ rules
Now we need to do the mapping in reverse: we want cgit’s links (e.g., /cgit/<repo-name>/about) to redirect to our external version of them (e.g., /code/<repo-name>/). These rules are straightforward: for each of the translation rules we created in the previous session, we add a corresponding redirect here.
location ~ ^/cgit/([^/]+)/about/$ {
return 302 /code/$1/;
}
location ~ ^/cgit/([^/]+)/?$ {
return 302 /code/$1/summary/;
}
location ~ ^/cgit/(.*)$ {
return 302 /code/$1$is_args$args;
}
[Update (2020-11-05): The last rule must have a $is_args$args at the end, so that query parameters are passed on in the redirect.]
The cherry on the top of the kludge
This set of rules will already work if all you want is to expose cgit’s URLs in a different form. But there is one thing missing: if we go to the cgit initial page (the repository list), all the links to repositories will be of the form /cgit/<repo-name>/, which our rules will translate to /code/<repo-name>/summary/. But we don’t want that! We want the links in the repository list to lead to the repo about page (i.e., /code/<repo-name>/, not /cgit/<repo-name>/). So what do we do now?
The solution is to pass a different base URL to cgit just for the initial page. So we add a zeroth rule (it has to come before all other /code/ rules so it matches first):
location ~ ^/code/$ {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /code;
fastcgi_param PATH_INFO /;
}
The difference between these and the other rules is that we pass SCRIPT_NAME with the value of /code instead of /cgit, so that in the initial page, the links are of the form /code/<repo-name>/ instead of /cgit/<repo-name>/, which means they will render cgit’s /<repo-name>/about/ page instead of /<repo-name>/.
Beautiful, huh?
Caveats
One thing you have to ensure with these rules is that every repo has an about page; cgit only generates about pages for repos with a README, so your links will break if your repo doesn’t have one. One solution for this is to create a default README which cgit will use if the repo does not have a README itself. For this, I have the following settings in my /etc/cgitrc:
# Use the repo readme if available. readme=:README.md # Default README file. Make sure to put this file in a folder of its own, # because all files in the folder become accessible via cgit. readme=/home/elmord/cgit-default-readme/README.md
EOF
That’s all I have for today, folks. If you have comments, feel free to, well, leave a comment.
Doing web stuff with Guile
2018-02-19 22:35 -0300. Tags: comp, prog, lisp, scheme, web, in-english
A few days ago I started working on Parenthetical Blognir, a rewrite of Blognir in Guile Scheme. In this post I'd like to talk a bit about some things I learned in the process.
Interactive development
I did the development using Geiser, an Emacs package for interactive Scheme development. It can connect with a running Scheme, and you can evaluate code from within Emacs, have completion based on the currently available bindings, etc.
The coolest part of this is being able to reevaluate function and class definitions while the program is running, and seeing the effects immediately. In this sense, GOOPS (the Guile Object Oriented Programming System, inspired by the Common Lisp Object System) is really cool in that you can redefine a class and the existing instances will automatically be updated to reflect the new class definitions (unlike, say, Python, in which if you redefine a class, it's an entirely new class, and instances of the old class will have no relationship with the new class).
One thing I realized is that you have to adapt your program a bit if you want to make the most of interactive development. For example, in Guile's web framework, there is a procedure (run-server handler), which starts up the web server and calls handler to serve each request. My request handler was a procedure named handle-request, so my code called (run-server handle-request). The problem is that this way run-server will be called with the value of handle-request at the time we started the server, and subsequent redefinitions of handle-request while the server is running will have no effect on the running server. Instead, I ended up writing something like:
(start-server (lambda (request body)
(handle-request request body)))
I.e., instead of calling handle-request directly, the server will call the anonymous function which, when called, will call handle-request. In this way, it will use the value of handle-request at each time the anonymous function is called, so it will see changes to the definition.
Another thing to take into account is that there may be some bindings you don't want to redefine when you reload a module, e.g., variables holding program state (in my case, a variable holding the blog object). For that, Guile provides a define-once form, which only defines a variable if it doesn't already exist.
One gotcha I encountered was when using parameters, the Scheme world equivalent of dynamically-scoped variables. Parameters in Guile have per-thread independent values, and since the web server and the REPL run in different threads, they may see different values for the same parameter. I ended up not using parameters anyway for other reasons (more on that later).
(web server)
Guile comes with a web framework of sorts, though it is pretty bare-bones. (Actually the main thing I missed in it was having to parse the request query and POST data by hand. At least it does provide a function to percent-decode URL components.) It has a philosophy of pre-parsing all headers into structured data types as a way of avoiding programming errors. It's an interesting idea; I have mixed feelings about it, but I think it's a valid idea to build a framework on (after all, if you're going the trouble of making a new framework, you might as well try some new ideas rather than creating yet another run-of-the-mill web framework).
You start the server by calling run-server with a callback (as mentioned above). Whenever a new request comes, the callback will be called with a request object and the request body as a bytevector. The callback must return (at least1) two values: a response object and a response body. Guile allows some shortcuts to be taken: Instead of a response object, you can pass an association list of response headers and the framework will automatically make a response object out of it. The response body may be either a string (which will be automatically encoded to the proper encoding, usually UTF-8), a bytevector, or a procedure; in the latter case, the procedure will be invoked with a port as an argument, and whatever you print to that port will be sent as the response body.
Rendering HTML
Guile comes with support for SXML, an S-expression based tree representation of XML. This means you can write things like:
(sxml->xml `(div (@ (class "foo"))
"Hello, world"))
and it will emit <div class="foo">Hello, world</div>. The nice thing is that strings appearing in the tree will be automatically escaped approprietely, so you don't have to worry about escaping (or forgetting to escape) data that may contain special characters, such as <, > or &.
That very feature was at first what led me not to want to use SXML, appealing though it was, to render Blognir pages. The reason is that post contents in Blognir come raw from a post file; I didn't want to parse the file HTML contents into SXML just to dump it again as HTML in the output2, and I saw no way to insert a raw string in the middle of an SXML tree bypassing the escaping in the output. So I began this adventure by printing chunks of HTML by hand. At some points I needed to escape strings to insert them in the HTML, so I wrote a small wrapper function to call sxml->xml on a single string and return the escaped string (by default sxml->xml prints to a port rather than returning a string).
When I got to the post comments form, where I have to do a lot of escaping (because all field values have to be escaped), I decided to use sxml->xml for once, for the whole form, rather than escaping the individual strings. I found it so nice to use that I decided to look up the source code for sxml->xml to see if there wasn't a way to insert raw data in the SXML tree without escaping, so I could use it for the whole page, not just the form. And sure enough, I found out that if you put a procedure in the tree, sxml->xml will call that procedure and whatever it prints is emitted raw in the result. This feature does not seem to be documented anywhere. (In fact, the SXML overview Info page says (This section needs to be written; volunteers welcome.). Maybe that's up to me!) By that point I had already written most of the rest of the page by printing HTML chunks, and I did not go back and change everything to use SXML, but I would like to do so. I did use SXML afterwards for generating the RSS feeds though, with much rejoicing.
Parameters – or maybe not
Parameters are used for dynamically scoped values. They are used like this:
;; 23 is the initial value of the parameter. (define current-value (make-parameter 23)) (define (print-value) (display (current-value)) (newline)) (print-value) ;; prints 23 (parameterize ([current-value 42]) (print-value)) ;; prints 42 (print-value) ;; prints 23 again
My original plan was to create a bunch of parameters for holding information about the current request (current-query, current-post-data and the like), so I wouldn't have to pass them as arguments to every helper request handling function; I would just bind the parameters at the main handle-request function, and all functions called from handle-request would be able to see the parameterized values.
The problem with my plan is that instead of returning the response body as a string from handle-request, I was returning a procedure for the web framework to call. By the time the procedure was called, handle-request had already finished, and the parameterize form was not in effect anymore. Therefore the procedure saw the parameters with their initial value rather than the value they had when the procedure was created. Oops!
Because closures don't close over their dynamic scope (that's kinda the whole point of dynamic scope), parameters ended up not being very useful for me in this case. I just passed everything as, ahem, parameters (the conventional kind) to the subfunctions.
Performance tuning
Despite its crude design, the original Blognir is pretty fast; it takes around 1.7ms to generate the front page in my home machine. I got Parenthetical Blognir at around 3.3ms for now. I'm sure there are still optimizations that can be done, and I may still try some things out, but right now I don't have any pressing need to make things faster than that.
I did learn a few things about optimizing Guile programs in the process, though. I used the ab utility (package apache2-utils on Debian) to measure response times, and Guile's statistical profiler to see where the bottlenecks were. I did not keep notes on how much impact each change I did had on performance (and in many cases I changed multiple things at the same time, so I don't know the exact impact of each change), but I can summarize some of the things I learned.
This is standard advice and applies to every programming language, but do use the profiler to find out performance bottlenecks. They often come from unexpected places, and it is far better to see the numbers than trying to guess where the bottlenecks might be.
Some things are slow because they take up CPU themselves, and some things are slow because they generate garbage, so your program spends more time in the garbage collector. The procedure currently taking the most time in Parenthetical Blognir is
%after-gc-thunk, and I still have not analysed it more carefully to determine where this is coming from.Guile has two versions of
format(the Guile counterpart toprintf): one from the(ice-9 format)module, written in Scheme, which supports various format specifiers; and a bare-bones one, written in C, available under the namesimple-format, which only supports the~aand~sformat specifiers with no qualifiers.3simple-formatis much faster than theformatfrom(ice-9 format), so if you only need the bare~aand~sformats and your program makes heavy use of them, I recommend usingsimple-format.My program was spending quite a bit of time on
read-stringto read post contents. It only reads the contents of a post to dump it into the response, andread-stringwill waste some time decoding the input from UTF-8 to Guile's internal string type, dynamically growing a string to the right size to fit the post contents, just to immediately decode it back to UTF-8 and discard the string as garbage. I found it more efficient to write a little function which takes two ports (the open post file and the open response port) and just copy the raw bytes in fixed-size chunks from one port to the other:(use-modules (rnrs bytevectors) (ice-9 binary-ports)) (define (pump-port in-port out-port) (let ([buffer (make-bytevector 65536)]) (let loop () (let ([count (get-bytevector-n! in-port buffer 0 65536)]) (when (not (eof-object? count)) (put-bytevector out-port buffer 0 count) (loop))))))For extra garbage reduction, you can reuse the buffer across calls (but be careful if the code may be called from multiple threads).
Conclusion
In general, I liked the experience of rewriting the blog in Guile. It was the first time I did interactive Scheme development with Emacs (previously I had only used the REPL directly), and it was pretty cool. Some things could be better, but I see this more as an opportunity to improve things (whether by contributing to existing projects, by writing libraries to make some things easier, or just as things to take into account if/when I decide to have a go again at trying to make my own Lisp), rather than reason for complaining.
There are still a few features missing from the new blog system for feature parity with the current one, but it already handles all the important stuff (posts, comments, list of recent comments, filtering by tag, RSS feeds). I hope to be able to replace the current system with the new one Real Soon Now™.
_____
1
If you return more than two values, the extra values will be passed back to the callback as arguments on the next call. You can use it to keep server state. If you want to use this feature, you can also specify in the call to run-server the initial state arguments to be passed in the first call to the callback.
2
And my posts are not valid XML anyway; I don't close my <p> tags when writing running text, for instance.
3
There is also a format binding in the standard environment. It may point to either simple-format or the (ice-9 format) format, depending on whether (ice-9 format) has been loaded or not.
Some thoughts on Twitter and Mastodon
2017-06-25 01:32 -0300. Tags: comp, web, privacy, freedom, life, mind, in-english
Since the last post I've been using Mastodon as my primary microblogging platform for posting, but I was still regularly reading and retweeting stuff on Twitter. A while ago Twitter started reordering tweets in my timeline despite my having disabled that option, just as I said could eventually happen (except much earlier than I expected). The option is still there and is still disabled, it's just being ignored.
Twitter brought me much rejoicing during the years I used it. I follow a lot of cool people there and I've had lots of nice interactions there. I found myself asking if I should accept some abuse from Twitter to keep interacting with those people, and I've been shocked at myself for even asking myself that. I've been using Twitter less and less as of late. (I'd like to be able to say I did it out of principles, but to be completely truthful I find the non-chronological timeline utterly annoying, and that has had as much to do with my leaving as principles.)
Although I switched to Mastodon as my Twitter replacement, Mastodon is not really "another Twitter". Having 500 rather than 140 characters to write initially felt like learning to talk again. Early on when I started using Mastodon, I was going to reply to a person's toot (that's what posts are called in Mastodon) with a short, not-really-one-full-sentence line that is the norm in Twitter. I wrote it down and was like "no, this kind of grunting a half-thought is not going to cut it here". It felt like Twitter's 140 character limit not only limited the kinds of things you could say, but also imposed/favored a "140-character mindset" of not finishing lines of thought or thinking with much depth. As I went on using Mastodon, I found myself writing thoughts I wouldn't have even tried to write in Twitter.
I still open up Twitter once in a while. Today I opened the mobile version in my desktop browser and noticed that the mobile version still shows a chronological timeline, still doesn't pollute the timeline with liked-but-not-retweeted tweets, and is much faster and cleaner than the desktop version. (I still have to un-fix the navigation bar via CSS, but I already had to do that in the desktop version anyway.) It's tempting to start using Twitter again through the mobile version, while it doesn't catch up with the new "features". I know I shouldn't, though. Even if the mobile version never caught up with the misfeatures (I suppose it eventually will, probably in short time), Twitter has already shown they're willing to throw stuff down their users' throats in the name of – what? I'm not even sure. Maybe they want to make Twitter more Facebook-like to attract Facebook users, even if that means alienating the people who used Twitter exactly because it was not like Facebook?
The funny thing is Twitter could simply provide some options for users to control their experience ("(don't) show tweets liked by your followers", "(don't) show tweets you liked to your followers", "(don't) reorder tweets" (the last one is already there, it just doesn't work)). This way they could cater to whatever new audience they have in mind and keep the users who liked how Twitter used to work. They just don't care to. I'm not really sure what are the motivations and goals behind Twitter's actions. For a really long time before the last changes it had been showing the "you might like" box (even if you clicked the "show me less like this" option (the only way to dismiss it) every time) and the "you might like to follow" box (even if you dismissed that too, and even though it also showed undimissable follow suggestions on the right pane anyway). I used to open Twitter pretty much every day, so it didn't really make sense as a user retention strategy. Maybe they want to incentivize people to do specific things on Twitter, e.g., throw in more data about themselves? (Yeah, there was the "add your birthday to your profile" periodic thing too.)
Meh.
Why the new like-based Twitter timeline is terrible
2017-05-31 21:56 -0300. Tags: comp, web, privacy, in-english
Recently, tweets which people I follow 'liked' (but not retweeted) started showing up in my Twitter timeline. Twitter had been showing the "you might like" box with such tweets for quite a long time, but they were separate from normal tweets, and you could dismiss the box (it would come back again after a while, though). Now those 'liked' tweets are showing up intermingled with the normal tweets, and there is no option to disable this.
Now, Twitter has been working hard on its timeline algorithms lately, and, at least initially, the liked tweets it added to my timeline were indeed stuff I liked, and they constituted just a small part of total tweets. That's not the case anymore: now liked tweets seem to be about one third of all tweets I see, and a smaller proportion of them interest me. Moreover, I simply don't want to see that many tweets. If I'm seeing all tweets I used to see plus liked tweets, and liked tweets comprise about a third of all tweets I see now, then I'm seeing about 50% more tweets, and I simply don't have the patience for so much tweetering; I already limit the number of people I follow so as to keep my timeline manageable.
But even if Twitter's algorithms were perfect and showed me only things I wanted to see in an ideal quantity, showing liked-but-not-retweeted tweets would already be bad, for a number of reasons:
'Likes' (formerly 'favorites') were a way to give fake Internet points to someone without being forced to share it with your followers. Sometimes I do this just because I don't think the content will be generally of interest to my followers (e.g., linguistics-based humor). But sometimes I may do it for more serious reasons, for instance, because I think the content might be offensive or be taken badly by some of my followers (e.g., religion-based humor). And sometimes I want to signal an approval to someone's opinion which might generate controversy or discussion if shared, but I don't really want to have a discussion about it with anyone at the time (e.g., some political views).
Likes have always been public in the sense that you could open up someone's profile and see a feed of everything they liked, but you had to actively stalk someone to see that. Now people who follow you don't have to do anything in particular to see the things you liked, so you have to work on the assumption that anything you like might show up in someone else's feed, which is annoying.
You don't see every tweet your followees liked; you only see some of them, and the selection is done by Twitter's algorithms, which of course are closed. At best (if the algorithms try to maximize showing things you like), this has the potential of creating a bubble effect of feeding you more and more with the things you already like and agree with, and filtering out differing views and opinions. At worst, the algorithms might try to maximize something else (e.g., things advertisers would like you to see rather than things you would like to see).
The bubbling effect is currently probably not as bad in Twitter as it is in Facebook because you still see all tweets your followees (re)tweet; you just see more tweets on the top of those. Note that Twitter already has an option of using a more Facebook-like timeline which reorders the tweets according to what its algorithms think you might be interested in more. It is currently opt-out, but it might stop being so in the future, the same way you used to be able to dismiss the "you might like" tweets but can't anymore.
As Twitter keeps trying brave new ways of monetizing its users, it's probably going to become more problematic from a privacy perspective. Meanwhile, we now have a quite viable decentralized, free, and usable social network (and I'm already there). The sad thing is that most of the people I follow will probably not migrate from Twitter, but as Twitter keeps getting worse in matters of privacy, transparency and usability, I'm becoming more inclined to leave it, as I have done before.
Update (2017-06-13): Today my Twitter timeline showed up out of order, at least temporarily, even though the "Show me the best Tweets first" options still appears disabled. That one came quick.
elmord.org
2017-02-10 23:52 -0200. Tags: about, comp, web, em-portugues
Então, galere: este blog está em vias de se mudar para elmord.org/blog. Eu ainda estou brincando com as configurações do servidor, mas ele já está no ar, e eu resolvi avisar agora porque com gente usando já tem quem me avise se houver algo errado com o servidor novo.
(Incidentalmente, eu também me mudei fisicamente nas últimas semanas, mas isso é assunto para outro post.)
Mas por quê?
Eu resolvi fazer essa mudança por uma porção de motivos.
No final do ano passado, a minha Internet de casa tinha ficado absurdamente instável (por motivos de "o proprietário da casa mexeu na fiação e a deixou exposta à chuva e ao sol por quase um ano e eu não sabia"). Eu costumava deixar alguns serviços rodando na máquina de casa, e estava impossível usá-la remotamente com a conexão caindo a cada 10 minutos e o IP trocando. Um colega de serviço me recomendou contratar uma VPS da Host1Plus, e assim o fiz (pela módica quantia de 8 pila por mês). Agora que eu já pago pela VPS anyway, não tem por que eu não hospedar o blog lá também.
O servidor da INF ainda está rodando PHP 5.2 num Debian 5, que não recebe mais atualizações de segurança desde 2012 (sim, esse post é 2015, e não, nada mudou). Como já mencionei naquele post, ter que programar em PHP 5.2 é bem annoying, e hospedando o blog no meu próprio servidor eu posso instalar um PHP mais recente.
More generally, programar em PHP é bem annoying, e tendo meu próprio servidor eu não preciso programar em PHP. Esperem uma reescrita do blog em Scheme, Real Soon Now™.
Ainda falando da INF, a rede da INF tem uma tendência a cair sempre que chove forte, e sempre chove forte no RS. Não que o Host1Plus seja uma maravilha de estabilidade, mas enfim.
Ainda falando da INF, a INF desabilitou o HTTPS em 2009~2010 por algum motivo, e assim ficou. No site novo eu tenho HTTPS, powered by Let's Encrypt e dehydrated.
É mais fácil dizer para as pessoas que o meu blog fica em elmord.org do que em inf.ufrgs.br/~vbuaraujo. Acho.
For great justice.
O plano qüinqüenal
Eu ainda não sei se essa migração vai ser definitiva (vai depender da estabilidade e performance do servidor novo), então pretendo fazê-la em dois passos:
Servidor novo como réplica do atual. Inicialmente, tanto o elmord.org/blog quanto o inf.ufrgs.br/~vbuaraujo/blog vão ficar servindo o mesmo conteúdo. As páginas do elmord.org ficarão apontando o inf.ufrgs.br como link canônico, i.e., search engines e afins vão ser instruídos a continuar usando a versão no inf.ufrgs.br como a versão "oficial" das páginas. Os comentários de ambas as versões serão sincronizados periodicamente (o que dá para fazer com rsync porque os comentários são arquivos texto).
Redirecionamento para o servidor novo. Se daqui a alguns meses eu estiver suficientemente satisfeito com o funcionamento do servidor novo, ele passa a ser o oficial, as páginas param de incluir o header de link canônico para o blog antigo, e o blog antigo passa a redirecionar para as páginas correspondentes do novo. Se eu não me satisfizer com o servidor novo, eu tiro ele do ar, o inf.ufrgs.br continua funcionando como sempre, e fazemos de conta que nada aconteceu.
EOF
Por enquanto é só. Se vocês encontrarem problemas com o site novo, queiram por favor reportar.
Como evitar que Google, Facebook, Twitter e a NSA saibam por onde você anda na Web
2013-07-13 22:53 -0300. Tags: comp, web, privacy, em-portugues
Agora que é um fato público e conhecido que os dados que você entrega ao Google, Facebook e companhia não estão em boas mãos (e se você acha que está tudo bem, queira assistir um videozinho), pode ser uma boa você reduzir a quantidade de informação a que eles têm acesso.
E graças aos botões de "Curtir", "Tweet", "+1" e similares, bem como as propagandas do Google, o Google Analytics, e o uso extensivo do googleapis.com, essas empresas recebem informação suficiente para ter uma boa idéia de por onde você anda na Web, mesmo quando você está navegando páginas fora desses serviços, a menos que você tome os devidos cuidados.
Existe um bocado de addons que você pode instalar no Firefox para reduzir a possibilidade tracking. (Se você usa o Chrome, é mais fácil você começar a usar o Firefox). Neste post, listo alguns deles e explico como eles podem ser usados para esse fim.
AdBlock Plus
O AdBlock Plus é um addon bem conhecido cujo uso primário é bloquear propagandas. Por si só, isso já é um começo, pois evita que os servidores de propaganda possam trackeá-lo. Porém, o AdBlock pode ser usado para bloquear quaisquer itens indesejáveis de terceiros em páginas. Por exemplo, suponha que você deseja bloquear acessos de outras páginas para o Facebook (há maneiras mais convenientes de atingir esse objetivo, todavia):
- Vá a alguma página que faça acesso ao Facebook.
- Clique no ícone do AdBlock e selecione Open blockable items (ou Abrir itens bloqueáveis).
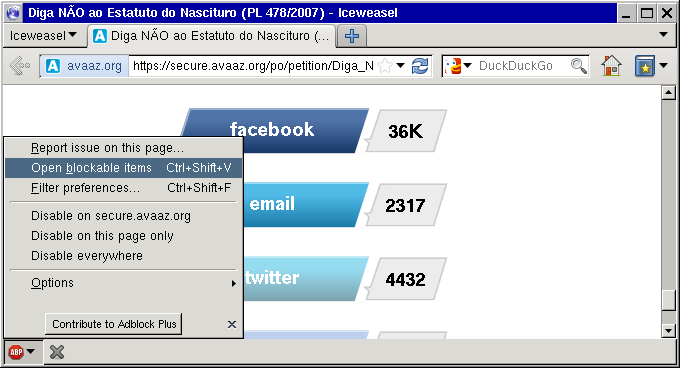
- Encontre algum dos acessos ao Facebook na lista e dê dois cliques sobre o mesmo.
- A janela que se abre apresentará várias possibilidades de regras de bloqueio. Selecione a mais apropriada (neste caso, facebook.net^; note que posteriormente você também deverá repetir o processo para o facebook.com).
- Clique no botão Advanced (ou Avançado). Este botão apresentará algumas opções adicionais à direita. Dentre elas, a mais útil é a Third-party only (ou Apenas terceiros); se marcada, essa opção impede o acesso ao facebook.net, exceto a partir do próprio facebook.net. Você pode achar isso útil se por algum diabo você ainda usa a rede social da NSA para se comunicar.
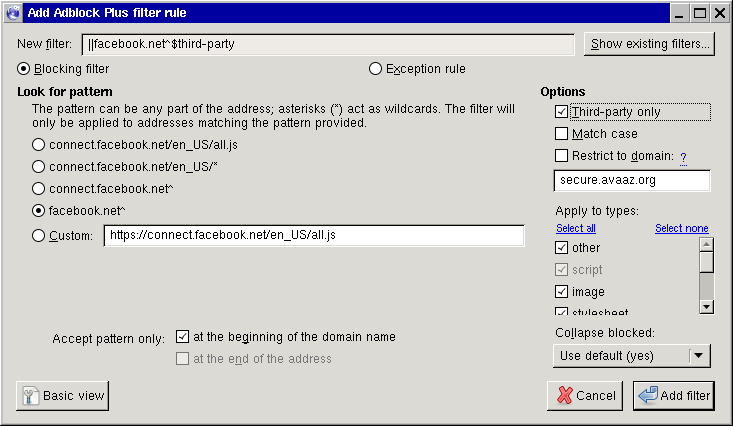
- Clique em Add filter (ou Adicionar filtro). Está feito!
Você pode bloquear outros sites (como facebook.com, twitter.com, google-analytics.com, scorecardresearch.com, etc.) da mesma maneira.
Por padrão, o AdBlock permite "ads não-intrusivos". Embora a idéia seja bem-intencionada, na prática isso significa que ele não bloqueia o Google por padrão, então é uma boa idéia desabilitar essa opção indo no menu do AdBlock, Filter preferences, primeira aba (Filter subscriptions), e desmarcar Allow some non-intrusive advertising.
Por padrão, o AdBlock faz atualizações automáticas da lista de sites a bloquear. Se você quiser evitar isso, abra o about:config, procure a opção extensions.adblockplus.subscriptions_autoupdate e dê dois cliques sobre ela para ajustá-la para false.
Disconnect
O Disconnect é um addon que já vem com uma lista padrão de sites de tracking conhecidos e bloqueia acessos aos mesmos a partir de sites de terceiros. Só descobri esse addon hoje, e como eu já uso o RequestPolicy, não cheguei a experimentá-lo direito, mas aparentemente ele funciona bem.
Smart Referer
Por padrão, sempre que o browser faz acesso a uma página a partir de outra (e.g., quando você clica em um link, ou quando uma página inclui uma imagem ou script de outra), o browser envia na requisição um header Referer, que diz qual é a proveniência do acesso (i.e., a página que continha o link ou a imagem ou script). O Smart Referer é um addon que faz com que o browser só envie esse header se a origem e o destino estiverem no mesmo domínio, o que impede o site de saber de onde você está vindo.
Já mencionei o Smart Referer antes por aqui, mas até recentemente não tinha me dado conta de quão importante ele é: uma quantidade enorme de sites usa serviços hospedados nos servidores do Google (jQuery, reCAPTCHA, Maps, entre outros), e por padrão, ao acessar esses serviços, o browser acaba informando ao Google pelo header Referer que página você está acessando. Com o Smart Referer, você evita enviar essa informação (a menos que o jQuery ou outro serviço se dê ao trabalho de enviar essa informação; pelo menos no caso do jQuery esse não parece ser o caso (ainda)).
O Smart Referer não exige configuração nenhuma, não adiciona ícone de toolbar nenhum, e faz o seu serviço quietinho sem incomodar ninguém.
HTTPS Everywhere
O HTTPS Everywhere é um addon mantido pela Electronic Frontier Foundation que traduz URLs HTTP de sites conhecidos para URLs HTTPS seguras. Por exemplo, toda vez que você acessa http://en.wikipedia.org, o addon substitui automaticamente a URL por https://en.wikipedia.org. Com isso, evita-se enviar informações não-encriptadas pela Web por descuido.
RequestPolicy
Um plugin que você pode achar útil é o RequestPolicy. Ele bloqueia todos os acessos de páginas a sites de terceiros por padrão (com exceção de uma pequena lista de acessos conhecidos, como por exemplo de wordpress.com para wp.com, e que você pode escolher na instalação), e permite adicionar exceções para sites individuais através de um ícone na barra de toolbars. O RequestPolicy é um dos plugins que melhor garante sua privacidade, às custas da inconveniência de ter que freqüentemente adicionar novas exceções para conseguir usar páginas. Ele também é útil para carregar páginas mais rápido em um 3G ou algum outro tipo de conexão lenta. Não recomendo muito para pessoas menos-que-paranóicas e que não vivam com uma conexão de 6kB/s, desde que você use alguma alternativa como o Disconnect.
Últimas observações
Uma lista de outros addons e serviços para assegurar melhor sua privacidade pode ser encontrada no PRISM Break.
Fugindo do assunto de addons, uma alternativa de serviço de e-mail para quem quer fugir do GMail é o SAPO, um provedor português. O SAPO Mail fornece 10GB de espaço e fica hospedado em Portugal, onde existe uma legislação decente de prote(c)ção de dados pessoais (dê uma olhada na política de privacidade dos camaradas).
Pidgin Off-the-Record
2013-06-07 21:33 -0300. Tags: comp, web, privacy, em-portugues
Acabei de descobrir um plugin chamado pidgin-otr (pacote pidgin-otr no Debian/Ubuntu), que permite realizar conversas encriptadas independentemente do protocolo de comunicação utilizado. O plugin funciona cifrando e decifrando mensagens individuais nos clientes, e transmitindo para o servidor o conteúdo cifrado como se fosse uma mensagem comum.
O plugin é bastante conveniente de usar. Para ativá-lo, basta instalar o pacote e habilitá-lo na janela de plugins do Pidgin (Tools > Plugins > Off-the-Record Messaging). A partir daí, as janelas de conversação apresentarão um ícone que permite iniciar uma conversa privada (desde que o outro usuário também possua o plugin). Pelo que eu entendi, uma vez que isso tenha sido feito para um usuário, conversas posteriores serão cifradas automaticamente por padrão.
Quem me contou foi o Reddit (em um post sobre a acesso da NSA a dados do Google, Apple, Facebook e diversas outras organizações estadunidenses).
fgetcsv: A cautionary tale
2013-05-18 01:52 -0300. Tags: comp, prog, web, php, rant, em-portugues
Quando eu reescrevi o blog system, eu resolvi manter o índice de posts em um arquivo CSV e usar as funções fgetcsv e fputcsv para manipulá-lo. Minha intuição prontamente me disse "isso é PHP, tu vai te ferrar", mas eu não lhe dei importância. Afinal, provavelmente seria mais eficiente usar essas funções do que ler uma linha inteira e usar a explode para separar os campos. (Sim, eu usei um txt ao invés de um SQLite. Eu sou feliz assim, ok?)
Na verdade o que eu queria era manter o arquivo como tab-separated values, de maneira que ele fosse o mais fácil possível de manipular com as ferramentas convencionais do Unix (cut, awk, etc.). As funções do PHP aceitam um delimitador como argumento, então pensei eu que bastaria mudar o delimitador para "\t" ao invés da vírgula e tudo estaria bem. Evidentemente eu estava errado: um dos argumentos da fputcsv é um "enclosure", um caractere que deve ser usado ao redor de valores que contêm espaços (ou outras situações? who knows?). O valor padrão para a enclosure é a aspa dupla. Acontece que a fputcsv exige uma enclosure: não é possível passar uma string vazia, ou NULL, por exemplo, para evitar que a função imprima uma enclosure em volta das strings que considerar dignas de serem envoltas. Lá se vai meu tab-separated file bonitinho. Mas ok, não é um problema fatal.
A segunda curiosidade é que a fgetcsv aceita um argumento "escape", que diz qual é o caractere de escape (\ por default). Evidentemente, você tem que usar um caractere de escape; a possibilidade de ler um arquivo em um formato em que todos os caracteres exceto o delimitador de campo e o "\n" tenham seus valores literais é inconcebível. Mas ok, podemos setar o escape para um caractere não-imprimível do ASCII (e.g., "\1") e esquecer da existência dele. Acontece que a fputcsv não aceita um caractere de escape, logo você não tem como usar o mesmo caractere não-imprimível nas duas funções. WTF?
Na verdade, agora testando melhor (já que a documentação não nos conta muita coisa), aparentemente a fputcsv nunca produz um caractere de escape: se o delimitador aparece em um dos campos, ele é duplicado na saída (i.e., a"b vira a""b). Evidentemente, não há como eliminar esse comportamento. Mas então o que será que faz o escape character da fgetcsv?
# php -r 'while ($a = fgetcsv(STDIN, 999, ",", "\"", "\\"))
{ var_export($a); echo "\n"; }'
a,z
array (
0 => 'a',
1 => 'z',
)
a\tb,z
array (
0 => 'a\\tb',
1 => 'z',
)
Ok, o escape não serve para introduzir seqüências do tipo \t. Talvez para remover o significado especial de outros caracteres?
a\,b,z array ( 0 => 'a\\', 1 => 'b', 2 => 'z', ) a b,z array ( 0 => 'a b', 1 => 'z', ) a\ b,z array ( 0 => 'a\\ b', 1 => 'z', )
Muito bem. Como vimos, o escape character serve para, hã... hmm.
Mas o fatal blow eu tive hoje, olhando a lista de todos os posts do blog e constatando que o post sobre o filme π estava aparecendo com o nome vazio. Eis que:
# php -r '
$h = fopen("entryidx.entries", "r");
while ($a = fgetcsv($h, 9999, "\t"))
if ($a[0]=="20120322-pi") var_export($a);'
array (
0 => '20120322-pi',
1 => 'π',
2 => '2012-03-22 23:53 -0300',
3 => 'film',
)
# LC_ALL=C php -r '
$h = fopen("entryidx.entries", "r");
while ($a = fgetcsv($h, 9999, "\t"))
if ($a[0]=="20120322-pi") var_export($a);'
array (
0 => '20120322-pi',
1 => '',
2 => '2012-03-22 23:53 -0300',
3 => 'film',
)
A próxima versão do Blognir deverá usar fgets/explode.
UPDATE: Aparentemente o problema só ocorre quando um caractere não-ASCII aparece no começo de um campo. Whut?
UPDATE 2:
"a b","c d" array ( 0 => 'a b', 1 => 'c d', ) "a"b","c"d" array ( 0 => 'ab"', 1 => 'cd"', ) "a\"b","c d" array ( 0 => 'a\\"b', 1 => 'c d', )