Posts com a tag: comp
O que é uma macro e por que diabos eu usaria uma?
2019-03-23 22:21 -0300. Tags: comp, prog, lisp, hel, fenius, em-portugues
No último post, eu divaguei um pouco sobre a implementação de macros em Hel, minha linguagem de programação experimental. Neste post, pretendo explicar para um público não-Líspico o que são macros e como elas podem ser úteis. /
Árvores
Quando escrevemos uma expressão do tipo 2+3 em um programa, o compilador/interpretador da nossa linguagem de programação tipicamente converte essa expressão em uma estrutura de dados, chamada árvore de sintaxe abstrata (AST, em inglês), representando as operações a serem realizadas. Em Hel, o operador quote permite visualizar a AST de uma expressão:
hel> quote(2+3) Call(Identifier(`+`), [Constant(2), Constant(3)])
Neste exemplo, a AST representa uma chamada ao operador +, com as duas constantes como argumento. Podemos manipular a AST para obter seus componentes individuais:
hel> let ast = quote(2+3) Call(Identifier(`+`), [Constant(2), Constant(3)]) hel> ast.head Identifier(`+`) hel> ast.arguments [Constant(2), Constant(3)] hel> ast.arguments[0] Constant(2) hel> ast.arguments[1] Constant(3)
Também podemos construir uma AST diretamente, chamando os construtores Identifier, Call, etc. manualmente ao invés de obter uma AST pronta com quote(). Assim, podemos escrever código que manipula ou gera novas ASTs, possivelmente utilizando componentes de uma AST já existente.
Agora, quando chamamos uma função, ela atua sobre o resultado dos seus argumentos, e não sobre a AST dos argumentos. Por exemplo, se eu definir uma função:
let f(x) = x
e a chamar como f(2+3), o valor de x dentro da função será 5, e não uma AST da expressão 2+3. Do ponto de vista da função, não há como saber se ela foi chamada como f(5) ou f(2+3) ou f(7-2): o valor de x será o mesmo. E se fosse possível escrever uma função que trabalhasse diretamente sobre a AST de seus argumentos? E se eu pudesse fazer transformações sobre essa AST, produzindo uma expressão diferente a ser calculada (por exemplo, alterando o significado de certos operadores ou palavras que apareçam na expressão)?
Pois é basicamente isso que é uma macro. Uma macro é uma função especial que, ao ser chamada, recebe como argumento a AST inteira da chamada, produz como resultado uma AST alternativa, que será usada pelo compilador/interpretador no lugar da AST original.
Mas pra que serve?
Em muitas linguagens, existe um comando for ou foreach para iterar sobre os elementos de uma lista. Em Python, por exemplo:
for x in [1, 2, 3]:
print(x)
Você, programador Hel, olha para esse comando e pensa "puxa, que legal!". Infelizmente, porém, (ainda) não existe um comando análogo em Hel. Porém, nós sabemos que (1) um for nada mais é do que uma repetição mudando o valor da variável a cada iteração; (2) podemos escrever uma função que implementa essa repetição; e (3) podemos escrever uma macro que transforma uma expressão do tipo for var in list { ... } em uma chamada de função correspondente. Vamos ver como isso funciona.
1º passo: a função
Nossa linguagem atualmente não conta com nenhum comando de repetição especializado. Porém, podemos escrever uma função recursiva que recebe uma lista e uma função a aplicar e, se a lista não for vazia, aplica a função ao primeiro elemento da lista e chama a si própria sobre o resto da lista, repetindo assim a operação até que só sobre a lista vazia.
let foreach(items, f) = {
if items != [] { # Se a lista não for vazia...
f(items.first) # Aplica a função ao primeiro elemento
foreach(items.rest, f) # E repete para o resto da lista.
}
}
Agora podemos chamar essa função com uma lista e uma função pré-existente para aplicar a cada elemento:
hel> foreach([1, 2, 3], print) 1 2 3
Ou podemos chamá-la com uma função anônima:
hel> foreach([1, 2, 3], fn (x) { print("Contemplando elemento ", x) })
Contemplando elemento 1
Contemplando elemento 2
Contemplando elemento 3
2º passo: a transformação
[Update (30/05/2019): O código desta seção está obsoleto. Há uma maneira muito mais simples de realizar a transformação descrita aqui nas versões mais recentes da linguagem.]
Agora o que gostaríamos é de poder escrever:
for x in [1, 2, 3] { print("Contemplando elemento ", x) }
ao invés de:
foreach([1, 2, 3], fn (x) { print("Contemplando elemento ", x) })
Para isso, vamos analisar a AST de cada uma das expressões e ver como podemos transformar uma na outra. Começando pela expressão pré-transformação:
hel> let source = quote(for var in list body) Phrase([Identifier(`for`), Identifier(`var`), Identifier(`in`), Identifier(`list`), Identifier(`body`)])
A expressão consiste de uma frase com uma lista de constituintes. Os constituintes que nos interessam aqui são a variável de iteração (constituinte 1, contando do zero), a lista sobre a qual iterar (constituinte 3), e o corpo (constituinte 4):
hel> source.constituents[1] Identifier(`var`) hel> source.constituents[3] Identifier(`list`) hel> source.constituents[4] Identifier(`body`)
Agora vamos analisar a expressão que queremos como resultado da transformação:
hel> let target = quote(foreach(list, fn (var) body)) Call(Identifier(`foreach`), [Identifier(`list`), Phrase([Identifier(`fn`), Identifier(`var`), Identifier(`body`)])])
Com isso, podemos escrever uma função que recebe uma AST da expressão origem e produz uma similar à expressão destino, porém substituindo Identifier(`list`), Identifier(`var`) e Identifier(`body`) pelos componentes extraídos da AST origem:
let for_transformer(source) = {
# Extraímos os componentes:
let var = source.constituents[1]
let list = source.constituents[3]
let body = source.constituents[4]
# E produzimos uma expressão transformada:
Call(Identifier(`foreach`), [list, Phrase([Identifier(`fn`), var, body])])
}
Será que funciona?
hel> for_transformer(Phrase([Identifier(`for`), Identifier(`var`), Identifier(`in`), Identifier(`list`), Identifier(`body`)])) Call(Identifier(`foreach`), [Identifier(`list`), Phrase([Identifier(`fn`), Identifier(`var`), Identifier(`body`)])])
Parece um sucesso.
3º passo: A macro
Agora só falta definir for como uma macro, pondo a nossa função for_transformer como o transformador de sintaxe associado à macro:
hel> let for = Macro(for_transformer)
E, finalmente, podemos usar nossa macro:
hel> for x in [1, 2, 3] { print("Eis o ", x) }
Eis o 1
Eis o 2
Eis o 3
E não é que funciona? Ao se deparar com o for, o interpretador identifica que trata-se de uma macro, e chama o transformador associado para converter a AST em uma nova AST. No nosso caso, o transformador monta uma AST correspondente a uma chamada a foreach, com uma função anônima cujo argumento é a variável de iteração e cujo corpo é o corpo do for. A AST resultante é então executada pelo interpretador, que chama a função foreach, que itera sobre cada elemento da lista chamando a função anônima gerada, imprimindo assim galhardamente os elementos da lista.
Conclusão
Macros nos permitem adicionar novas construções à linguagem, através de funções que transformam a AST das novas construções em ASTs de construções já existentes. É basicamente uma maneira de ensinar ao compilador/interpretador como interpretar novas construções em termos das que ele já conhece.
Na versão atual de Hel, é necessário manipular e construir as ASTs manualmente. O ideal seria ter um mecanismo para facilitar a extração de componentes e construção de novas ASTs sem ter que obter e construir cada nodo individual... mas um dia chegamos lá.
Hel has macros
2019-03-20 23:31 -0300. Tags: comp, prog, pldesign, lisp, hel, fenius, in-english
Hel got macros today. That came about through a different (and simpler) route than I had envisioned; today I'm going to ramble a bit about it.
As I described previously, I decided to abandon Lisp syntax and experiment with a more conventional syntax, while trying to preserve the flexibility to define new commands that looked just like the builtin ones (such as if, for, etc).
Because the new syntax was more complicated than Lisp's atoms and lists, I thought Lisp-style procedural macros would not be very convenient to use in the new language. So from the start, I had the idea of providing template-based macros (a la Scheme's syntax-rules) to match the various syntactic forms and describe replacements. I've been struggling with the problem of finding a good notation for matching pieces of code [all the while looking at Rust and Dylan for inspiration], with unsatisfying results. Meanwhile, I have been working on simpler parts of the language, such as adding support for defining functions, if/then/else, and such.
Yesterday I tackled various other low-hanging fruit problems, such as adding preliminary support for lists, tuples, indexing (list[i]), strings, and records. Rather than reinventing a record structure, I implemented Hel records in terms of R6RS records1. One consequence of this is that Hel programs can manipulate not only their own record types, but also the records of the host Scheme implementation.
Once I had that, I realized I could just drop the record types for the AST into the Hel standard environment, and now I could manipulate syntax trees from Hel! By this point, I could write functions taking a syntax tree as an argument and returning a syntax tree as a result. This is basically what a macro is. All I needed then was a way to mark those functions as macros, so that the interpreter could identify them as such and call them with the unevaluated syntax tree as an argument, rather than the evaluated arguments (i.e., so that m(x+y) is called with the syntax tree for x+y rather than the result of calculating x+y).
* * *
What I did when I dropped the AST constructors in the Hel environment was, in a sense, making Hel homoiconic (although not with a code representation as direct as Lisp's, and some would argue that this does not count as true homoiconicity; it does not really matter). Although this is somewhat obvious (I exposed the syntax tree types, therefore I can manipulate syntax trees), there is a difference between a formal/logical understanding and an intuitive understanding of something; and seeing the immediate power that something as simple as exposing the language's syntax tree to itself yielded was eye-opening, even though I have programmed in a language with exposed syntax trees as its hallmark feature for years – I guess this so normal in Lisp you eventually take it for granted, and don't really think about how magic this is.
The most surprising part of this for me was how easy it was to add this power to the language: just expose the AST constructors, add half a dozen lines to the interpreter to recognize macro calls, and bam!, we have macros and homoiconicity. I started wondering why more modern interpreted languages don't expose their ASTs in the same way. I think there are a number of factors in the answer. One of them perhaps is the fact that most of the popular scritping languages are implemented in C, and in C it would take special effort to expose the AST to the interpreted language, compared to (R6RS) Scheme where I was able to easily implement generic support for exposing any record/struct types from the host language to the interpreted language. Reflection was a big win here. (I'm not clear how much dynamic typing had a fundamental role in making this easy too. Perhaps it would be possible to do in a statically-typed host language too, but I wonder how easy would it be; it certainly seems it would not be as easy, but that's something I have to think harder about.)
Another factor is that the Hel syntax tree, although more complex than Lisp, is still much simpler than the typical programming language, by design. There were only eight AST constructors to expose to the interpreted language: Phrase, Constant, Identifier, Tuple, Array, Block, Call, and Index. (In the current version there is an extra node, Body, which is used for the whole program and as the content of a Block; I expect to remove it from the exposed AST in the future, since it's just a list of phrases.) Infix and prefix operators are internally converted to Call nodes, with the operator as the callee and the operands as arguments. There is still room for simplification: Call and Index (i.e., f(x, y) and v[i, j]) have essentially the same fields and might be unified in some way; and Tuple and Array might be unified in a single Sequence node. I don't know to what extent this is desirable, though.
By contrast, Python, for example, does expose its AST, but it has a huge set of syntax nodes, and its representation can change with each Python release. Of course this is a danger for Hel too: once the AST is exposed, it's harder to change without breaking client code. Some abstraction mechanism might be necessary to allow evolution of the AST representation without breaking everyone's macros. On the other hand, the Hel AST is much less likely to change, since new language constructs don't generally require changing the AST.
Open problems
Although it's already possible to write macros in Hel, a pattern-matching interface would still be more convenient to use than directly manipulating the syntax nodes. However, it might be easier to implement the pattern-matching interface as a macro, in Hel, in terms of the current procedural interface, than as special code in the interpreter.
The other problem to handle is hygiene: how to keep track of the correct binding each identifier points to, and how this information is exposed in the AST. I still have to think about this.
_____
1 And although I have spoken unfavorably about R6RS in the past, I'm glad for its procedural interface for record creation and inspection. I think I have some more good things to say on R6RS in the future.
The Lispless Lisp
2019-03-08 01:16 -0300. Tags: comp, prog, pldesign, lisp, hel, fenius, in-english
For a while I have been trying to design a nice Lisp-based syntax for Hel, trying to fit things like type information and default arguments in function definitions, devising a good syntax for object properties, etc., but never being satisfied with what I come up with. So a few days ago I decided to try something else entirely: to devise a non-Lisp syntax while maintaining a similar level of flexibility to define new language constructs. And I think I have come up with something quite palatable, though there are a few open problems to solve.
The idea is not entirely new. I know of at least Elixir, which is homoiconic but has more variety/flexibility in its syntax, though it has a bunch of hardcoded reserved words; and Dylan, which seems to have a pretty complex macro system, though maybe a little more complex than I'd wish. My non-Lisp Hel syntax has a bunch of hardcoded symbols (( ) [ ] { } , ; and newline), and the syntax for numbers and identifiers is hardcoded too (but that is hardcoded even in Lisp, though Common Lisp has reader macros to overcome this problem to an extent), but there are no reserved keywords, and I find it easier to read and analyze than Dylan. I hope you like it too (though feel free to comment in any case).
A taste of syntax
Here is a sample of the new syntax:
if x > 0 {
print("foo")
return x*2
} else {
print("bar")
return x*3
}
That looks like a pretty regular language, but the magic here is that none of the "keywords" is hardcoded. This is interpreted as a command if with the four arguments x > 0, the first block, else, and the second block. It is up to the operator/macro bound to the variable if to decide what to do with these arguments.
There are some caveats here, the most notable one being that the else must appear in the same line as the closing brace of the first block, otherwise it would be interpreted as an independent command rather than a part of the if command. I think this is an acceptable price to pay for the flexibility of not having a limited, hardcoded set of commands.
How does it work
The central component of the syntax is the command, or perhaps more precisely the phrase, since "command" gives the impression of a separation between statements and expressions which does not really exist in the syntax. A phrase is a sequence of space-separated constituents. A constituent is one of:
- a constant, such as 42 or "hello";
- an identifier, such as x;
- an infix expression (consituent operator constituent), such as 2*3;
- a prefix expression (operator constituent), such as -x;
- a function call, such as f(x, y);
- an indexing operation, such as vec[i];
- a tuple, such as (1, 2, 3);
- an array, such as [1, 2, 3];
- a parenthesized expression, such as (42);
- a block, such as { print("foo") }.
The arguments of a function call, indexing operation, parenthesized expression, and the elements of tuples and arrays are themselves phrases (i.e., you can have an if inside a function call).
Parsing of constituents is greedy. When looking at a series of tokens such as if x > 0 { ... } and trying to determine where a consituent ends and the next one starts, the parser will consider each consituent to be the longest sequence of tokens from left to right that can be validly interpreted as a constituent. In this example:
- The first constituent is if, since if x is not a valid constituent.
- The second constituent is x > 0, since x > 0 { (or any longer sequence) cannot be a valid constituent.
- The third constituent is the whole block.
Phrases are separated by newlines or semicolons. To avoid the effect of a newline, a \ can be used at the end of the line (as in Python). Within parentheses or brackets, newlines are ignored (also as in Python).
That's pretty much all there is to it, in general lines. Except...
Operator precedence
An operator is any sequence of one or more of the characters ! @ $ % ^ & * - + = : . < > / ? | ~. So + and * are operators, but so are ++ and |> and @.@.
One open problem with this syntax is how to handle operator precedence in a general way. In my current prototype, I have hardcoded the precedence of the arithmetic operators, but I need to have sane precedence rules for user-defined operators.
One way is to allow the user to specify the precedence for custom operators (like the infixl and infixr declarations in Haskell). The problem is that this means a program cannot be parsed without interpreting the fixity declarations, which I find annoying, especially given that operators can be imported from other modules, and being unable to parse (read in Lisp parlance) a program without compiling the dependencies is deeply annoying from a Lisp perspective. Another problem is that it is not only hard to parse for the parser, it's hard to parse for the human too.
Another way is to have a fixed rule to assign each operator a precedence. I remember seeing a language once which gave each operator a precedence based on its first character (so, for example, *.* would have the same precedence as *). [Update: I don't remember which language it was, but it turns out that Scala does the same.] I like this solution a lot because it's easy for the human to know the precedence of an operator they've never seen before. The problem is reconciling this with the natural precedences expected from some operators (for instance, = and == usually have different precedences). I still have to think about this. Suggestions are welcome.
[Update: Maybe it makes more sense for the last character to determine precedence, since we want things like += to have the same precedence as =. On the other hand, an operator like => makes more sense as having the same precedence as = than >. Don't = and > have the same precedence anyway, though, since == and > do?]
Gotchas
Constituents vs. phrases
The consituent parsing rules may cause some surprises. Consider the following example:
let answer = if x > 0 { 23 } else { 42 }
In principle, this looks like assigning the result of the if to the variable answer. However, the parsing rules as stated above will lead to this being parsed as the sequence of constituents:
- let
- answer = if
- x > 0
- { 23 }
- else
- { 42 }
which is not quite what was intended. To use the if expression (which is a whole phrase, not a constituent) as the right-hand side of =, one would have to surround it with parentheses.
Commas delimit phrases
The arguments of a function call are phrases, not constituents, so an if expression can appear as the argument of a function call without having to surround it with an extra pair of parentheses on the top of those already required by the function call. But function arguments are delimited by commas, so, to avoid ambiguity, commas are not allowed to appear outside parentheses. For example, you cannot have a command like:
for x, y in items { ... }
because in a function call like:
f(for x, y in items { ... })
it would be ambiguous whether this is a single argument or two. The solution is to require:
for (x, y) in items { ... }
instead.
This also means that import foo, bar must be import (foo, bar) instead, though this limitation might be lifted outside parentheses.
Function calls vs. constituent+tuple
A space cannot appear between a function and its argument list. The reason is that we don't want for (x, y) in list to be interpreted as containing a function call for(x, y), nor do we want for x in (1, 2, 3) to be interpreted as containing a call in(1, 2, 3). I don't typically write spaces between a function and its arguments anyway, but I feel ambivalent about this space sensitivity. Perhaps the most important thing here (and in the above gotchas as well) is to have good error messages and (optional, on by default) warnings when things go wrong. For example, upon seeing something that might be a function call with a spurious space inside:
foo.hel:13: error: `foo` is not a command foo.hel:13: hint: don't put spaces between a function and its argument list 13 foo (x, y)
This might be harder for the macros (e.g., for identifying that the call in(1, 2, 3) it received as argument was meant to be two separate constituents), but I think it can be done, especially for rule-based macros (as opposed to procedural ones).
A different solution is to get rid of tuples entirely and use for [x, y] instead, except this does not really solve the problem because this is ambiguous with the indexing operation.
That's all for now
I already have a prototype parser, but it's pretty rough, and I still have to work on the interpreter, so I have not published it yet. If you have comments, suggestions, constructive criticism, or two cents to give, feel free to comment.
The road to Hel (is paved with good intentions)
2019-01-04 00:54 -0200. Tags: comp, prog, pldesign, lisp, hel, fenius, in-english
2019 might just be the year of Hel on the desktop. I mean, not really, but I would like to talk a bit about my prospects for Hel going forward.
For those who don't know, Hel (huangho's Experimental Language/Lisp) is my playground for experimenting with programming language design and implementation ideas. The Hel 0.1 compiler was a very crude translator from a simple Lisp-like language to C, similar in spirit to lows. Hel 0.2 was a bit of an improvement, in that it at least had the rudiments of an intermediate representation. The goal for Hel 0.2 was to be a superset of a subset of R5RS Scheme (i.e., Hel and R5RS would have a common subset), and the compiler itself would be written mostly in this subset; the idea was to eventually be able to compile the Hel compiler with either a Scheme implementation or with the Hel compiler itself, thus bootstrapping the language (i.e., being able to compile the compiler with itself).
My goals have changed a bit, though. First of all, I'm now interested in exploring more the language side rather than the implementation side of the project. I think an interpreter might serve my goals better than a compiler, since it is easier to change and test ideas. The compiler can come later.
Second, I'm not so keen anymore in having a large common subset with Scheme. Multi-shot continuations (call/cc) have always been out of the subset, but as of late I'm willing to question things as basic as cons cells. I may not get that far away from Scheme, but when exploring design options I definitely don't want to be constrained by compatibility. So bootstrappability can come later too.
Third, because I want to write an interpreter, but I don't want it to be terribly slow, I'll probably be switching implementation platform. So far I had been doing development on GNU Guile, but I'll probably switch to either Chez Scheme (a pretty fast R6RS Scheme implementation), or SBCL (a pretty fast Common Lisp implementation). SBCL has the advantage of having more libraries available (and Common Lisp itself is a larger language than that provided by Chez), while Chez has the advantage of being (in principle) closer to Hel (although that's kind of moot if bootstrapping is not an immediate goal anymore). I thought SBCL would also be faster than Chez, but in my highly scientific benchmark (running (fib 45) on each implementation), Chez is actually faster out of the box, though SBCL is faster if type declarations are provided.
So what are my goals for Hel 0.3? Well:
Implementation-wise, one of my major goals is debuggability. I want to have a Lisp which can give proper stack traces, with proper line numbers, in the presence of macros, and show function arguments in the stack trace.
- If a macro call (m) expands to a function call (f), I would like to be able to see both calls in the stack trace, even though the macro call of course is not really in the stack because it happened at compile time. But the fact that the call to (f) was generated by a macro can be stored in the debug information somehow together with the line number information. (I don't expect this to be particularly easy, or particularly hard; but it's a goal.)
Language-wise, I want:
Optional types, with a lightweight syntax for type declarations;
Explicit indication of mutability, with more things immutable by default (strings, lists). Mutability is an always-present part of APIs in Scheme and Common Lisp (both language standards are very explicit in describing data sharing between function arguments and results, which values can or cannot be mutated, etc.); I think this really ought to be more explicit in the data types themselves. I have described a proposal for handling mutability before, but nowadays I'm more inclined to simply have mutable and immutable variants of lists, dictionaries and such; it's less elegant but easier to implement and use efficiently. We'll see how this goes. The important thing is to make mutability explicit in the data types (and their printed representation).
A concise notation for declaring and using new data types, reading and printing them, doing pattern matching, reflection, etc., to reduce the temptation to Use Lists For Everything™.
There are other things (some of which I intend to write about in the future), but I think these are the most important ones.
Wish everyone a happy new year, and may our living-dead open source projects thrive in 2019.
Why (not) boxes?
2018-08-28 23:28 -0300. Tags: comp, prog, pldesign, lisp, in-english
In the previous post I discussed an idea for dealing with mutable data in a Lisp-like programming language by using mutable boxes and immutable everything-else, with a bunch of optimizations. One of the usual suspects asked me what was the advantage of this scheme over just declaring things const as one would in a language like C/C++. At first I did not have an answer ready. This is one of those situations where you are so stuck in your own perspective that some questions don't even occur to you.1 The immediate answer was that I was thinking in the context of a dynamically-typed language, so an immutability declaration like const2 was out of the picture. But there is more to it.
If I were to give a really complete answer, I would have to begin answering why I want dynamic rather than static typing. I started this post originally by trying to explain exactly that, but there is way more to say about it than I have the energy to do right now. For now let's just take for granted that I'm designing this framework in the context of a dynamically-typed languaged.
But I could still have a dynamically-typed equivalent of the const declaration: just shift the constness to the dynamic type of the object. So vectors and other composite objects would have a flag indicating whether they are mutable or not. I discussed this possibility at the end of the previous post, but I also commented I didn't find that solution as satisfying. But why not?
Semantic clarity
One thing I like about the mutability-as-boxes model is that it seems to makes it easier to think "equationally" about mutability: instead of mutability being an inherent property of vectors (and other data structures), mutability is an 'embellishment' which can be added to any data structure (by putting it into a box), and it seems more or less obvious (to me, anyway) what will be the expected behavior when adding or removing mutability from something (or rather, when adding or removing something from mutability). For example, if vectors were inherently mutable or immutable, then I have to know what operations exist to convert one type into the other, and what happens to the original (if I make an immutable vector out of the mutable one, will the new vector reflect further changes in the original (like a C const reference), or is it an independent, never-changing copy?). Of course, when you learned the programming language you would learn about those details and be done with it, but the boxes model seems to suggest the answers by itself: if I extract a vector (immutable, like all vectors) from a mutable box, I would expect that further changes to the box contents won't affect the vector I just extracted (because changing the box contents means replacing one vector with another, not changing the vector itself); and if I have an (immutable) vector v around and I put it inside a box, I would expect that further changes to the box contents won't affect my original v (for the same reason: if I change the box contents, I'm replacing v with a new vector, so it's not v anymore). In fact, in the previous post I have mostly wondered about how to implement the model efficiently, rather than what the correct behavior of each operation should be, because that part did not seem to raise any questions.
There is a flip side to this: although it is easier (to me, anyway) to think about the semantics of the mutability operations, the optimizations required to make it work well make it harder to think about the performance of the written code. That's the sufficiently smart compiler problem: a sufficiently smart compiler (or runtime) can turn something that would in principle be expensive into something fast, but then you change a small thing in your code in a way that the optimization cannot handle, and suddenly the performance of your program drastically changes. You end up having to know which cases the implementation can optimize, which makes up for the semantic simplicity. Unless you can make sure the optimization will handle all 'reasonable' cases (for varying values of 'reasonable'), this can be a problem.
Equality
Object equality is a more complicated concept than one might expect. There are multiple notions of equality around – some languages have multiple operators for different kinds of equality (for example, == and === in JavaScript, or eq?, eqv? and equal? in Scheme). One type of equality that's given particular prominence in Scheme is the idea of object equivalence, embodied in the eqv? predicate: two objects are equivalent iff no operation (other than the equality predicates themselves) can tell them apart. Mutability is particularly important for object equivalence: two mutable objects (say, two vectors [1 2 3] and [1 2 3]), unless they are one and the same object in memory, are never equivalent, even if they have the same contents, because you can tell them apart by modifying one and seeing if the other changes as well (i.e., they might cease from having the same contents in the future). On the other hand, two immutable objects of the same type and with the same contents are equivalent, because there is in principle no operation that can tell them apart. (Of course the implementation might provide a function to return the address of each object in memory, which would allow us to tell the objects apart. But let's not concern ourselves with that.) Another notion of equality is that of equality of contents, embodied in the equal? predicate: two objects are equal if they are of the same type and have the same contents, even if they are mutable.
When you have a lookup data structure such as a dictionary, you have to decide which kind of equality you will use to compare the keys in the data structure with the key being looked up. Scheme hash table implementations typically require one to specify the equality operator explicitly, because strings are mutable, so you want equal? if your keys are strings, but in other cases you may want to distinguish objects that are not equivalent in the above sense, so you want eqv?.
But if you make strings and vectors immutable, you can compare them with eqv?, and the cases where you want to actually use equal? for hash table lookup mostly go away. And you generally don't want mutable keys in your hash tables anyway (because if you mutate the object that was the original key, typically your hash table stops working because now the key changed but is still hashed under the old key's hash); we tolerate that in Scheme only because strings (and lists, and vectors) are mutable and we want to be able to use them as keys. So if mutability is isolated by boxes, now we can make hash table lookup use object equivalence (eqv?) by default and not worry about explicitly choosing the right predicate for hash table lookup. (Having a sensible default predicate for hash table lookup is important, among other cases, if you want to have literal syntax for hash tables, i.e., if you want to be able to write a literal hash table like {"foo": 1, "bar": 2} in your code without having to say "hey, by the way, the keys are compared by equal? in this case".)
You can still use boxes as keys in a hash table. But since boxes are mutable, a box is only eqv? to the very same object in memory, so you have to use the same box object as the key when you store a value in the table and when you look the value up. This is actually useful if you want to store information about the box itself rather than the contents. But what if I want to look up based on the box contents? Well, then you unbox the contents and look it up! Which expresses intent far better, if you ask me. (This is not entirely equivalent to an equal?-based hash table lookup because you may have boxes inside boxes which would all have to be unboxed to achieve the same effect. Not that this is a very common use case for hash table keys.)
Could we not do the same thing with the mutability flag model? In that model, eqv? would check the mutability flag; objects with the mutability flag on would only be equivalent if they were one and the same, and objects with the mutability flag off would be compared for contents. It would work, but would not be as pretty, if you ask me. However, as long as mutability is easily visible (for example, mutable objects would be printed differently, say like ~[1 2 3] if the mutability flag is on), it could work fine.
Mutable boxes are useful on their own
In Scheme, variables are mutable: you can use (set! var value) on them to change their values. The problem is, variables are not first-class entities in Scheme, so you cannot pass them around directly. So if you want to share mutable state across functions, you have to put the variable in some place where all the interested functions can see it; I remember once having moved subfunctions into another function just so they could all share the same mutable variable. Alternatively, you can create a mutable data structure and pass it around to the relevant functions – and the box is the simplest mutable data structure you can use, if all you want is to share one single mutable cell around. So mutable boxes are useful even if you don't intend to make them the one single source of mutation in the language. And since they are already there, why not just go ahead and do just that? (I am aware that "why not?" is not exactly the most compelling argument out there.)
Another case: cons-cell based lists are somewhat annoying to use with mutation. Suppose you have a list in a variable x, and you pass it around and it ends up in a variable y in another part of the program. If you append things to the tail of x by mutating the tail, both x and y will see the new items, because the tail is reachable from both x and y. But if you append things to the front of x, y won't see the new items in the front, because the new elements are not reachable from the old list tail. If you put the whole mutable list inside a box and passed the box around, both x and y would have the same view of the mutable object. And if you took the list out of the box and put it on another variable z, it would become immutable, so either you see the same changes to the list as everyone else, or you isolate yourself from all subsequent mutations, but it will not happen that you will see some changes to the (tail of the) list and not others (to the front).
Conclusion
I hope I have been able to show why I find the mutability-as-boxes model appealing. I'm not saying it does not have problems (on the contrary, I have already said it has problems), I'm just trying to show what is the point of the whole thing.
_____
1 This is kinda disturbing when you think about it. How many other questions am I not asking?
2 Well, const is not really about the immutability of the data, it's more about the permission to modify a piece of data from a given reference. That is, if a function is declared as taking a const char * argument, that means that the function is not supposed to modify the data pointed to, but it does not mean that the region will not be changed through other references. In other words, it's about requiring something from the user of the reference, but not about providing a guarantee to the user of the reference. A true immutability declaration would both forbid the user from modifying the data and ensure to them that the data will not change during use. Immutability in a language like Rust works like this (except immutable is the default, and mutability is explicitly declared).
An approach to mutation
2018-08-01 22:19 -0300. Tags: comp, prog, lisp, pldesign, in-english
I've been around lately with an idea for handling mutation in a new Lisp-like programming language. Most of these ideas are probably not new – in fact, while doing a little research I've found out about Clojure's transients, which embody some of the same ideas – and the parts that are possibly new are not necessary good. But I want to write this down for future reference, so there we go.
DISCLAIMER: This is one of those programming language design posts exploring a bunch of ideas and reaching no conclusion. Read at your own peril.
Some context
The problem with mutation is when the mutable data is shared with other parts of the program – especially when you don't know what parts of the program share the same data. For example, suppose you call a method blog_post.get_tags(), and it returns you a list ["comp", "prog", "lisp"] – can you mutate this list? For example, if I were to sort it, or remove elements from it, can I do it in-place, or I would be mutating a list used internally by the blog_post object and thus inadvertently affecting other parts of the program? Without looking at the method's source code, we don't know. If we wanted to be sure not to break anything, we would have to make a copy of the list and change the copy instead.
What if I am the person writing the get_tags() method? Should I always return a new copy of the list, wasting some memory and cycles but ensuring that whoever calls my function won't be able to affect the internal fields of the blog_post? Or should I always return the same list object, thus avoiding a new allocation but relying on the caller to do the right thing?
Now consider the strings inside that list. If I were to convert them to upper-case, should I do it in-place, or copy them first? In a language like C, this is the same problem as before: you have to know whether get_tags() gives you a copy of the original strings (which you can freely modify), or the internal strings used by blog_post (which you should not modify). But in a language like Java or Python, this problem does not come up: since strings are immutable in those languages, the only way to 'change' them is by making a new string, so modifying them in-place is not an option. On the other hand, the writer of the get_tags() method can now happily return the internal strings of the blog_post object, since they can be sure the strings cannot be modified by external code.
If you make all data structures immutable, you eliminate this problem – and that's the purely-functional approach, taken by languages like Haskell. Clojure is similar in making the core data types (such as lists, vectors and hashmaps) immutable, and having controlled forms of mutability. In traditional Lisps like Scheme and Common Lisp, on the other hand, most composite data types (including lists, vectors and strings) are mutable. The standards of those languages are careful in describing which functions always return freshly allocated data and which return values that may share parts with the function's arguments. This is basically part of the contract of those functions, which you have to know whenever you want to mutate values generated by them. The situation in traditional Lisps is somewhat aggravated by the fact that linked lists may share a tail: two lists (1 3 7 5) and (2 7 5) may actually share the same cons cells for the (7 5) part. In a mostly functional setting, this is okay, but if we want to mutate anything, we have to be extra careful not to be inadvertently changing something else. In this example, sorting the second list in place may end up messing the first list.
What I'm interested in is finding a middle ground between full immutability and full mutability. I want to be able to return immutable data from functions, so I can know the consumers of that data won't inadvertently change it, and I also want to be able to create mutable data which can be modified in place. It would also be nice to be able to use mutable data for temporary processing and make it immutable after we are ready. And I want to be able to tell at a glance if I'm dealing with mutable or immutable data.
So here is the idea…
The idea
First, we make all basic composite data types (lists, vectors, dictionaries, strings, etc.) immutable. Then we add a single mutable box type. Values of the box type have a single mutable field. This idea is at least as old as ML's ref type, so nothing new so far. I will use the notation &val to mean a box containing val, and the expression (set! box val) changes the contents of the box box to val. I will also use @ (read at) for the indexing function, so (@ vec idx) means the idxth element (starting at 0) from vector vec. (@ box) with no indices means to extract the box's contents.
So now we can make a mutable cell with an immutable vector inside, e.g., &[1 2 3]. We cannot mutate the vector directly, but we can replace the whole vector with another immutable vector. That may be elegant and all, but it's not as convenient as a mutable array, nor as efficient. There are some tricks we can play here, though.
The first trick is to make the assignment operator (set!) recognize vector indexing as its first argument, so if v is the vector-containing box &[1 2 3], we can write (set! (@ v 0) 42) to replace the vector [1 2 3] with the vector [42 2 3] inside the box. It looks like we are mutating the vector's first element, but actually we are replacing the whole original immutable vector with a new immutable vector with a different element at position 0.
This gets us convenience, but it's still inefficient: if I write a loop to mutate all elements of the vector, it will generate a fresh new vector on each iteration. But then comes the second trick: how can we tell the difference between a mutable cell with an immutable vector inside from an actual mutable vector? If we make the difference invisible to the programmer, then we can mutate the vector in-place as an optimization. So (set! (@ v 0) 42) syntactically looks like mutating a vector element, semantically means replacing the whole vector with a new one, but implementationally actually works by mutating the vector element anyway. I'm not sure about the wisdom of this double layer of self-cancelling illusions, but let's explore this idea further.
Let's call the naive implementation using a mutable box with an immutable vector inside, well, the naive implementation. And let's call the implementation which underlyingly uses a mutable vector to represent the box+vector combination the smart implementation (with the full understanding that it may actually be too smart for its own good, or maybe not smart enough to make this idea work well).
The most basic operation you can do with a box is extracting the contents. In the naive implementation, that's just returning the value inside. In the smart implementation, we must simulate this by copying the current contents of the mutable vector into a freshly allocated immutable vector and returning that. A user can then observe the difference between the two implementations by taking the contents of the same box twice and checking whether the results are eq? to each other, i.e., whether they are the same object in memory.
It seems to me that the solution to this problem is to ditch object identity for immutable objects from the language, i.e., get rid of the lower-level eq? operation (Python's is), or at least relegate it to a library of lower-level operations. Immutable objects should only be compared by its contents, not by identity: if I compare [1 2 3] with [1 2 3], it should not matter whether they are separate objects in memory or not: they have the same contents and that's what matters. The only way to tell two distinct objects with the same contents from each other (apart from eq?) is by mutating one of them and seeing if the other changes as well; but if the objects are immutable, this distinction disappears.
A possible optimization to reduce the amount of copying when extracting a box's contents is to return the actual underlying vector, but mark the box as copy-on-write, i.e., we postpone the copy to the next time we need to mutate the vector inside the box. If the box is not mutated afterwards, the vector is never copied. The problem with this may be performance: we need to check the copy-on-write flag before every change to the vector, and the whole point of these optimizations is performance. Sure, we avoid a copy, but we slow down every write to the vector. This is aggravated by the fact that this flag must be synchronized across threads, lest we end up with two threads making new copies and clobbering each others' view of the box.
Speaking of which, doesn't thread synchronization throw this whole idea out of the window anyway? Extracting the contents of a box must be an atomic operation, but someone might be mutating the underlying vector while we are copying it into a new immutable vector to return it. This is okay as long as we can guarantee that the resulting copy represents one possible atomic state of the box at the time of the extraction, but consider the following scenario:
- The box
boriginally contains&[1 2 3 4 5]. - Thread 1 evaluates
(def v (@ b)). The implementation starts to copy the elements into a new immutable vector. - Right after thread 1 copies
1, thread 2 evaluates(set! (@ b 0) 10). Nowbis&[10 2 3 4 5]. Thread 1 keeps on with its copying. - Thread 2 evaluates
(set! (@ b 4) 50). Nowbis&[10 2 3 4 50]. - Thread 1 finishes copying. Because the copy saw the second mutation but not the first one, the resulting copy has
[1 2 3 4 50]. - However,
[1 2 3 4 50]has never been a state ofb: the only statesbhad were[1 2 3 4 5],[10 2 3 4 5], and[10 2 3 4 50]. Thus, the illusion that the box contains an immutable vector is broken.
To avoid this problem, the implementation would have to acquire a lock (or use some other form of thread synchronization) when extracting the contents of a box, thus slowing down what should be a cheap operation. The copy-on-write solution avoids the copy incoherence problem, because the copying happens from the now-immutable vector to the new mutable one, and not the opposite, so we know that the origin will not change mid-copy. But as we have seen, we need to ensure synchronization of the copy-on-write flag, so it's pretty much the same.
Maybe this synchronization requirement is a good thing: maybe we want copies to be atomic anyway, and this way the semantics of the language guarantees that. But maybe this is an unnecessary overhead most of the time.
Even if we go with the copy-on-extract solution, we can avoid copying in the case of extracting the object from the box and then discarding the box (e.g., if we want to create a mutable vector, do a bunch of mutating operations on it, and then make it immutable) by providing an (unbox! b) operation which returns the contents and sets the box contents to nil (or whatever other value to indicate that the box is "empty"). Because we know the vector will not be mutated again, we can just return the underlying vector and call it immutable. This is basically what Clojure's persistent! operation does (though I didn't know that when I had this idea).
Let's consider some other problems and optimizations.
Putting it back in the box
What about sequences of transformations? For example, suppose I implement a filter function, which takes a predicate function and a vector and returns a new vector containing only the elements for which the predicate function returns true, like this:
(def (filter pred vec)
(let ([result &[]])
;; Collect satisfying items in the mutable result vector...
(for [item in vec]
(when (pred item)
(push! item result)))
;; And then return the contents as an immutable vector.
(unbox! result)))
What if I want to, say, filter a vector and then reverse it? If filter is written like this, I get an immutable vector back, so I would have to copy it into a mutable vector again just so I can reverse it. If only filter had not called unbox! at the end, I could have reversed it in-place without a new allocation! But if I don't unbox!, I will have to always manually unbox the result when I want to, and most of the time I do want an immutable result.
There is a possible trick to help us here: if we unbox a value just to immediately box it back again, we can actually keep using the same underlying storage with no copying. The problems with this optimization are: (1) We must be able to know that no other references to the object have been created between the unboxing and the re-boxing, and basically the only way to do this is with some sort of reference counting. Reference counting has its share of problems (cyclic data structures never reach count zero, we need to synchronize count updates across threads), so relying on an optimization which requires us to use reference counting is not good. (2) We need to make sure the reference count does not inadvertently rise above 1, which would preclude the optimization. Since there may be more going on under the scenes in the compiler/interpreter than reaches the eye, this would be an unreliable optimization, that sometimes does not trigger for non-obvious reasons.
An alternative to use reference counting would be to do this analysis at compile-time, either through some form of escape analysis (which is hard to do across functions), or some crazy type system with uniqueness types (like Rust's borrow checker), which does not mesh well with my goal of a dynamically typed language.
Nested data structures and sharing
What if I put nested data inside a box, like &[[1 2] [3 4]]? Should the sub-vectors become underlyingly mutable too? If so, when should we stop recursing through the structure, which could contain other composite data types in it? Should we do it lazily, using copy-on-write as we mutate the inner vectors? The implementation of this can get tricky. If I access (@ b 0), should I get an immutable [1 2], or should I get a mutable &[1 2] which shares the same memory as the original element, so that mutations on the &[1 2] vector are reflected on the &[[1 2] [3 4]] one?
I'm too tired to even analyse the possibilities right now.
Refactoring code to change data mutability
Suppose I have a data structure with a bunch of immutable fields, say, (Person name age) and I decide I want to make the age field mutable. In our conceptual framework, this means wrapping the value of the field in a mutable box, e.g., (Person "Hildur" &22), i.e., the field itself remains immutable, but its value is a mutable cell. That looks nice, and makes all mutability readily visible, but it also means that we have to change all code using the age field to extract the value from the box, even code that does not mutate the value.
Maybe this is a good thing: if the code was written under the assumption that the value does not change, maybe it is good that we have to revise everything when we turn it mutable. On the other hand, this makes it harder to try things out in code and run it to see what happens, and for I long time I have defended the ability to run incomplete (and even wrong) programs while prototyping. However, I also want to be able to run optional static checks, and it's easier to do so when code is explicit about its intentions. So there we go.
An alternative: mutability as a flag
An alternative to the mutability-as-boxes approach is just to make all composite data structures carry a 'mutable' flag. We can still use the notation &[1 2 3] to mean a vector with the mutable flag on. We can provide an operation like Clojure's persistent! which turns the mutability flag of an object off. An operation to turn it back on would be more dangerous, but might be useful for debugging purposes (though it's the kind of thing you can be certain will be abused if added to the language (though Lisps have traditionally always preferred to empower the user rather than impose decisions on them)).
In this scenario, the semantics of (set! (@ v 0) 42) is to actually modify the vector in-place, so we don't need the double illusion trick. If we want to return an immutable version of a mutable data structure without losing the mutability, we have to explicitly copy it. Perhaps more descriptive of intention, we may have a non-destructive persistent operation which returns an immutable version of a value, which may or may not actually involve a copy (it may actually use copy-on-write behind the scenes). Thread synchronization has to be done explicitly, otherwise you assume the risks of getting a partially-modified copy. This is somewhat unsatisfying, but inconsistencies across threads could happen with boxes anyway whenever you had to work with more than one box, so a better solution to synchronization is needed anyway.
(In)conclusion
This idea of using mutable boxes + immutable data structures + optimization tricks had been haunting me for a week and seemed really appealing at first, but thinking more deeply about it, it does have its share of problems. Maybe it's a cool idea anyway, maybe not. I have to think more about it. Said research will require more and abundant funding.
My take on the GitHub-Microsoft conundrum
2018-06-04 19:50 -0300. Tags: comp, freedom, in-english
Today the acquisition of GitHub by Microsoft was announced. Lots of people (myself included) have expressed their concerns about the consequences of this acquisition. Some people worried that Microsoft would end up ruining GitHub the same way it did to Skype. Some worried that it could be part of a traditional embrace, extend, extinguish move to kill off competition. Some worried that they could change the terms of service to grant themselves more rights over the code that is hosted on GitHub (that was my first worry, and I've seen it reflected elsewhere on Mastodon). At the same time, many people have countered that the new GitHub CEO will be a person friendly to open-source (Nat Friedman, founder of Xamarin), that Microsoft's stance towards open source has changed a lot in the last years, and that probably not much will change in the GitHub service.
I have reflected for a while about what should I do, and I decided that I will move my projects away from GitHub.
Here is my take on this: It does not matter whether Microsoft will ruin GitHub or not. To keep my personal projects on GitHub would be endorsing Microsoft, and I don't want to do this. It's not (only) that the company has a terrible track of mistreating the FOSS community. It's not (only) about what the company has done in the past. It's that in the present Microsoft still regularly mistreats its users, by pushing spyware on them (in the form of Windows 10 telemetry), by pushing ads on them (in the Windows 10 equivalent of the start menu), by de-decentralizing Skype and thus facilitating surveillance, by taking control away from users over their own systems (e.g., by forcing updates upon users and making it really difficult to disable automatic reboot), and so on. (This article has a nice list of bad things Microsoft has done in the past, which should be kept in mind too, but my point is that even if you ignore the past and look just at the present, there's plenty of reasons to dislike Microsoft.)
I don't want to endorse or support this company in any way, and I feel that keeping my projects there (and by implication requiring other people to use their services if they want to create issues, contribute code, etc.) is a form of endorsement. Therefore my decision is to move away.
I won't do this immediately, though. Although I have already decided that I will move away from GitHub, I still haven't decided where I will move to. The acquisition is not yet complete, and I will take my time to consider my options – whether I will move to some other code hosting service such as GitLab or BitBucket, or whether I will host my own server (and if so, which server software I will use), or whether I will go bare-bones and just have plain Git repositories and home pages for each project. I'm also wondering if this might be a good time to move away from Git and give Fossil a try.
I also may keep my GitHub account (assuming they don't make radical changes to the terms of service or the nature of the service), so I can open and comment on issues of projects still hosted there, and so I can point to whatever new place I decide to host my stuff on in my profile.
Bypassing Android's Factory Reset Protection on an Asus ZenFone Go
2018-05-15 00:03 -0300. Tags: comp, android, in-english
Modern Android versions come with a security (?) mechanism which requires the user to log in with a Google account previously used on the phone after a factory reset.
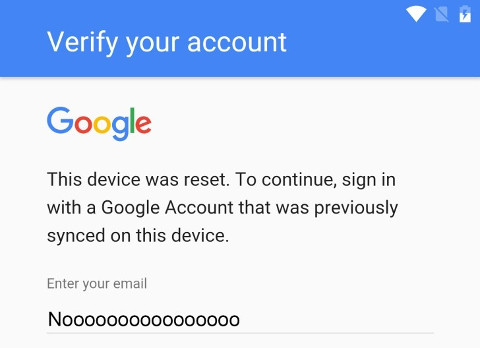
Picture source: Softpedia
There are dozens of different instructions for how to bypass this protection on the web, but none of the ones I tried to follow worked on the phone in question, an Asus ZenFone Go (ZB452KG). There are probably multiple firmware versions around for this phone model alone, so what works on one phone may not work on another. However, the various tutorials I found helped me discover a method that did work on my phone.
Ingredients: You will need a non-Google e-mail account to add to the phone, as well as the IMAP and STMP settings for your e-mail provider. You can remove this account after we're finished.
The goal: The goal of this exercise is to disable the Google apps in the phone settings: if they are disabled, the setup wizard will skip the account validation step. The trick is how to get to the phone settings before unlocking it.
Steps:
Follow the setup wizard until you get to the account validation screen. I recommend that, at the beginning of the wizard, you choose English as language, so that the Google app names all begin with "Google" and so are listed all together and are easier to find.
Select the e-mail field to open up the keyboard, tap the "⋮" button, select "Share", and "GMail".
Click "Skip" at the initial GMail screen. GMail will ask you to add an account. Configure your non-Google account here.
When you get to the compose message screen, tap the "⋮" button on the top right, choose "Settings", hit "⋮" again, and "Manage accounts". It will say "You're about to go to the Settings app …"; hit "Continue". Now we're at the phone settings!
Select "Apps", go to the "All" tab, and select the "Google Account Manager" app. Select "Force stop", and then "Disable". (You'll be asked to confirm these actions.)
Note: I actually disabled a bunch of other apps with names beginning with "Google" (such as "Google Services Framework") when I did this; I think this is not strictly necessary, but you can try it if disabling just "Google Account Manager" does not work.
Go back to the beginning of the setup wizard and follow the normal setup steps. Now at the point it would ask you for a Google account, it should ask for your name and surname instead. If this happens, it worked! Just finish the wizard and you'll have your phone unlocked.
If it does not work, try to go to "Settings > Apps > All" again and force stop the "Setup Wizard" applications (there are two of them on my phone), and then try to restart the wizard (you may have to turn your phone off and on again for that).
If you wish, go back to Settings and re-enable the apps you disabled. You can now also remove your IMAP e-mail account if desired.
Doing web stuff with Guile
2018-02-19 22:35 -0300. Tags: comp, prog, lisp, scheme, web, in-english
A few days ago I started working on Parenthetical Blognir, a rewrite of Blognir in Guile Scheme. In this post I'd like to talk a bit about some things I learned in the process.
Interactive development
I did the development using Geiser, an Emacs package for interactive Scheme development. It can connect with a running Scheme, and you can evaluate code from within Emacs, have completion based on the currently available bindings, etc.
The coolest part of this is being able to reevaluate function and class definitions while the program is running, and seeing the effects immediately. In this sense, GOOPS (the Guile Object Oriented Programming System, inspired by the Common Lisp Object System) is really cool in that you can redefine a class and the existing instances will automatically be updated to reflect the new class definitions (unlike, say, Python, in which if you redefine a class, it's an entirely new class, and instances of the old class will have no relationship with the new class).
One thing I realized is that you have to adapt your program a bit if you want to make the most of interactive development. For example, in Guile's web framework, there is a procedure (run-server handler), which starts up the web server and calls handler to serve each request. My request handler was a procedure named handle-request, so my code called (run-server handle-request). The problem is that this way run-server will be called with the value of handle-request at the time we started the server, and subsequent redefinitions of handle-request while the server is running will have no effect on the running server. Instead, I ended up writing something like:
(start-server (lambda (request body)
(handle-request request body)))
I.e., instead of calling handle-request directly, the server will call the anonymous function which, when called, will call handle-request. In this way, it will use the value of handle-request at each time the anonymous function is called, so it will see changes to the definition.
Another thing to take into account is that there may be some bindings you don't want to redefine when you reload a module, e.g., variables holding program state (in my case, a variable holding the blog object). For that, Guile provides a define-once form, which only defines a variable if it doesn't already exist.
One gotcha I encountered was when using parameters, the Scheme world equivalent of dynamically-scoped variables. Parameters in Guile have per-thread independent values, and since the web server and the REPL run in different threads, they may see different values for the same parameter. I ended up not using parameters anyway for other reasons (more on that later).
(web server)
Guile comes with a web framework of sorts, though it is pretty bare-bones. (Actually the main thing I missed in it was having to parse the request query and POST data by hand. At least it does provide a function to percent-decode URL components.) It has a philosophy of pre-parsing all headers into structured data types as a way of avoiding programming errors. It's an interesting idea; I have mixed feelings about it, but I think it's a valid idea to build a framework on (after all, if you're going the trouble of making a new framework, you might as well try some new ideas rather than creating yet another run-of-the-mill web framework).
You start the server by calling run-server with a callback (as mentioned above). Whenever a new request comes, the callback will be called with a request object and the request body as a bytevector. The callback must return (at least1) two values: a response object and a response body. Guile allows some shortcuts to be taken: Instead of a response object, you can pass an association list of response headers and the framework will automatically make a response object out of it. The response body may be either a string (which will be automatically encoded to the proper encoding, usually UTF-8), a bytevector, or a procedure; in the latter case, the procedure will be invoked with a port as an argument, and whatever you print to that port will be sent as the response body.
Rendering HTML
Guile comes with support for SXML, an S-expression based tree representation of XML. This means you can write things like:
(sxml->xml `(div (@ (class "foo"))
"Hello, world"))
and it will emit <div class="foo">Hello, world</div>. The nice thing is that strings appearing in the tree will be automatically escaped approprietely, so you don't have to worry about escaping (or forgetting to escape) data that may contain special characters, such as <, > or &.
That very feature was at first what led me not to want to use SXML, appealing though it was, to render Blognir pages. The reason is that post contents in Blognir come raw from a post file; I didn't want to parse the file HTML contents into SXML just to dump it again as HTML in the output2, and I saw no way to insert a raw string in the middle of an SXML tree bypassing the escaping in the output. So I began this adventure by printing chunks of HTML by hand. At some points I needed to escape strings to insert them in the HTML, so I wrote a small wrapper function to call sxml->xml on a single string and return the escaped string (by default sxml->xml prints to a port rather than returning a string).
When I got to the post comments form, where I have to do a lot of escaping (because all field values have to be escaped), I decided to use sxml->xml for once, for the whole form, rather than escaping the individual strings. I found it so nice to use that I decided to look up the source code for sxml->xml to see if there wasn't a way to insert raw data in the SXML tree without escaping, so I could use it for the whole page, not just the form. And sure enough, I found out that if you put a procedure in the tree, sxml->xml will call that procedure and whatever it prints is emitted raw in the result. This feature does not seem to be documented anywhere. (In fact, the SXML overview Info page says (This section needs to be written; volunteers welcome.). Maybe that's up to me!) By that point I had already written most of the rest of the page by printing HTML chunks, and I did not go back and change everything to use SXML, but I would like to do so. I did use SXML afterwards for generating the RSS feeds though, with much rejoicing.
Parameters – or maybe not
Parameters are used for dynamically scoped values. They are used like this:
;; 23 is the initial value of the parameter. (define current-value (make-parameter 23)) (define (print-value) (display (current-value)) (newline)) (print-value) ;; prints 23 (parameterize ([current-value 42]) (print-value)) ;; prints 42 (print-value) ;; prints 23 again
My original plan was to create a bunch of parameters for holding information about the current request (current-query, current-post-data and the like), so I wouldn't have to pass them as arguments to every helper request handling function; I would just bind the parameters at the main handle-request function, and all functions called from handle-request would be able to see the parameterized values.
The problem with my plan is that instead of returning the response body as a string from handle-request, I was returning a procedure for the web framework to call. By the time the procedure was called, handle-request had already finished, and the parameterize form was not in effect anymore. Therefore the procedure saw the parameters with their initial value rather than the value they had when the procedure was created. Oops!
Because closures don't close over their dynamic scope (that's kinda the whole point of dynamic scope), parameters ended up not being very useful for me in this case. I just passed everything as, ahem, parameters (the conventional kind) to the subfunctions.
Performance tuning
Despite its crude design, the original Blognir is pretty fast; it takes around 1.7ms to generate the front page in my home machine. I got Parenthetical Blognir at around 3.3ms for now. I'm sure there are still optimizations that can be done, and I may still try some things out, but right now I don't have any pressing need to make things faster than that.
I did learn a few things about optimizing Guile programs in the process, though. I used the ab utility (package apache2-utils on Debian) to measure response times, and Guile's statistical profiler to see where the bottlenecks were. I did not keep notes on how much impact each change I did had on performance (and in many cases I changed multiple things at the same time, so I don't know the exact impact of each change), but I can summarize some of the things I learned.
This is standard advice and applies to every programming language, but do use the profiler to find out performance bottlenecks. They often come from unexpected places, and it is far better to see the numbers than trying to guess where the bottlenecks might be.
Some things are slow because they take up CPU themselves, and some things are slow because they generate garbage, so your program spends more time in the garbage collector. The procedure currently taking the most time in Parenthetical Blognir is
%after-gc-thunk, and I still have not analysed it more carefully to determine where this is coming from.Guile has two versions of
format(the Guile counterpart toprintf): one from the(ice-9 format)module, written in Scheme, which supports various format specifiers; and a bare-bones one, written in C, available under the namesimple-format, which only supports the~aand~sformat specifiers with no qualifiers.3simple-formatis much faster than theformatfrom(ice-9 format), so if you only need the bare~aand~sformats and your program makes heavy use of them, I recommend usingsimple-format.My program was spending quite a bit of time on
read-stringto read post contents. It only reads the contents of a post to dump it into the response, andread-stringwill waste some time decoding the input from UTF-8 to Guile's internal string type, dynamically growing a string to the right size to fit the post contents, just to immediately decode it back to UTF-8 and discard the string as garbage. I found it more efficient to write a little function which takes two ports (the open post file and the open response port) and just copy the raw bytes in fixed-size chunks from one port to the other:(use-modules (rnrs bytevectors) (ice-9 binary-ports)) (define (pump-port in-port out-port) (let ([buffer (make-bytevector 65536)]) (let loop () (let ([count (get-bytevector-n! in-port buffer 0 65536)]) (when (not (eof-object? count)) (put-bytevector out-port buffer 0 count) (loop))))))For extra garbage reduction, you can reuse the buffer across calls (but be careful if the code may be called from multiple threads).
Conclusion
In general, I liked the experience of rewriting the blog in Guile. It was the first time I did interactive Scheme development with Emacs (previously I had only used the REPL directly), and it was pretty cool. Some things could be better, but I see this more as an opportunity to improve things (whether by contributing to existing projects, by writing libraries to make some things easier, or just as things to take into account if/when I decide to have a go again at trying to make my own Lisp), rather than reason for complaining.
There are still a few features missing from the new blog system for feature parity with the current one, but it already handles all the important stuff (posts, comments, list of recent comments, filtering by tag, RSS feeds). I hope to be able to replace the current system with the new one Real Soon Now™.
_____
1
If you return more than two values, the extra values will be passed back to the callback as arguments on the next call. You can use it to keep server state. If you want to use this feature, you can also specify in the call to run-server the initial state arguments to be passed in the first call to the callback.
2
And my posts are not valid XML anyway; I don't close my <p> tags when writing running text, for instance.
3
There is also a format binding in the standard environment. It may point to either simple-format or the (ice-9 format) format, depending on whether (ice-9 format) has been loaded or not.
Managing windows and taking notes from Emacs
2018-02-14 00:02 -0200. Tags: comp, emacs, in-english
EXWM and Org mode are two entirely unrelated pieces of Emacs software. However, by virtue of both running in Emacs, they can be combined in some interesting ways.
EXWM
EXWM is a window manager written in Emacs Lisp. I think this is the craziest thing I've seen written in Emacs Lisp so far, and yet it moves. It basically turns Emacs into a tiling window manager. Your windows become Emacs buffers, and you can manage them with the usual Emacs commands for splitting windows, changing focus, switching buffers, and so on. (I learned about it here.)
As a window manager, I don't think it does anything very interesting compared to other tiling window managers. Its real power comes from being integrated into Emacs. This means I can always use Emacs commands no matter what window I am in (for example, if I want to open a file, I can hit C-x C-f no matter what program currently has focus).
This also means it can be customized and scripted in Emacs Lisp. For example, one thing I did with it is make it display "urgent" windows (those that would usually blink in the taskbar) in my Emacs mode line. So far, that's not very interesting, because with a conventional desktop environment I would already have windows highlighted in the taskbar. But what I have also done is customize it so that some windows are detected as "urgent" even though they don't set the urgency window manager hint. For example, I have windows with titles like (1) Skype (i.e., windows with unread messages) tagged as urgent as well.
Another nice trick you can do with EXWM is send fake keypresses to windows. For example, one thing I did was to make a variant of Emacs' insert-char command (which allows entering characters by their Unicode name or hex codepoint) which can be called from any window, by asking for the character name, putting it into the clipboard, and then sending a fake C-v to the application.
My EXWM config file is here. It has grown a bit complex, and some things are still a bit kludgy/glitchy, but I've been using it for some 3-4 months for now. Take the parts you like from it.
Org-capture
Org is an Emacs mode for managing structured data in plain-text format, though that description doesn't really do justice to the thing. It can manage to-do lists, agendas, handle tables in awesome ways, and many more things. It can also export files to various formats, including Beamer presentations, which I've written about before. I'm still learning how to use it and all of its features, and I'm trying to use it for more things, including blogging. (I wrote some kludgy code to export Org files to blog posts, but I found out afterwards that it would be better to create a new export backend inheriting from the built-in HTML export backend. Still have to learn more about this though.)
One cool feature of Org mode is org-capture, a command for taking notes with little flow interruption from what you are currently doing. Once you have it all configured, you can hit something like C-c c j to create an entry using the journal template. The entry will be pre-filled according to the template, and can include, for example, a link to the place you called the command from. For example, if you call it from a w3m buffer, the new note will contain a link to the web page you were visiting. If you call it from some source code, it will create a link to the place you were in the source code file. Org can recognize a variety of different buffer types, and create links appropriate to the context you called it from. You can easily make it recognize new kinds of context by defining new functions and adding them to org-store-link-functions.
Combining the two things
The most immediately observable advantage of using Org-capture in conjunction with EXWM is that you can call it from anywhere, not just regular Emacs buffers, because now Emacs commands work from any window. No matter whether you are seeing a file or reading something in Firefox, you can just type C-c c j to take a note. I find this really nice.
Another advantage is that because you can add new functions to org-store-link-functions, and all your windows are now Emacs buffers, you can actually make org-capture recognize the context of non-Emacs windows too. This is especially useful for browser windows: you can make the link inserted in the note reflect the page you are visiting. Although I'm not aware of a clean way to extract the current URL from a browser window, you can make do by faking the keypresses of C-l (to select the address bar) followed by C-c (to copy the contents to the clipboard), and then reading the clipboard contents from Emacs. Like this:
;; Grab address from the browser.
(defun elmord-exwm-get-firefox-url ()
(exwm-input--fake-key ?\C-l)
(sleep-for 0.05) ; Wait a bit for the browser to respond.
(exwm-input--fake-key ?\C-c)
(sleep-for 0.05)
(gui-backend-get-selection 'CLIPBOARD 'STRING))
;; org-store-link functions must either return nil (if they don't recognize
;; the context), or call `org-store-link-props' with the appropriate link
;; properties and return non-nil.
(defun elmord-exwm-org-store-link ()
(when (and (equal major-mode 'exwm-mode)
(member exwm-class-name '("Firefox" "Firefox-esr")))
(org-store-link-props
:type "http"
:link (elmord-exwm-get-firefox-url)
:description exwm-title))) ; Use window title as link description.
;; Finally, we add the new function to the list of known store-link functions.
(add-to-list 'org-store-link-functions 'elmord-exwm-org-store-link)
I find this really cool.
That's all, folks
I have more things I'd like to write about Emacs, but that's it for now.
« Mais recentes / Newer posts | Mais antigos / Older posts »