My take on the GitHub-Microsoft conundrum
2018-06-04 19:50 -0300. Tags: comp, freedom, in-english
Today the acquisition of GitHub by Microsoft was announced. Lots of people (myself included) have expressed their concerns about the consequences of this acquisition. Some people worried that Microsoft would end up ruining GitHub the same way it did to Skype. Some worried that it could be part of a traditional embrace, extend, extinguish move to kill off competition. Some worried that they could change the terms of service to grant themselves more rights over the code that is hosted on GitHub (that was my first worry, and I've seen it reflected elsewhere on Mastodon). At the same time, many people have countered that the new GitHub CEO will be a person friendly to open-source (Nat Friedman, founder of Xamarin), that Microsoft's stance towards open source has changed a lot in the last years, and that probably not much will change in the GitHub service.
I have reflected for a while about what should I do, and I decided that I will move my projects away from GitHub.
Here is my take on this: It does not matter whether Microsoft will ruin GitHub or not. To keep my personal projects on GitHub would be endorsing Microsoft, and I don't want to do this. It's not (only) that the company has a terrible track of mistreating the FOSS community. It's not (only) about what the company has done in the past. It's that in the present Microsoft still regularly mistreats its users, by pushing spyware on them (in the form of Windows 10 telemetry), by pushing ads on them (in the Windows 10 equivalent of the start menu), by de-decentralizing Skype and thus facilitating surveillance, by taking control away from users over their own systems (e.g., by forcing updates upon users and making it really difficult to disable automatic reboot), and so on. (This article has a nice list of bad things Microsoft has done in the past, which should be kept in mind too, but my point is that even if you ignore the past and look just at the present, there's plenty of reasons to dislike Microsoft.)
I don't want to endorse or support this company in any way, and I feel that keeping my projects there (and by implication requiring other people to use their services if they want to create issues, contribute code, etc.) is a form of endorsement. Therefore my decision is to move away.
I won't do this immediately, though. Although I have already decided that I will move away from GitHub, I still haven't decided where I will move to. The acquisition is not yet complete, and I will take my time to consider my options – whether I will move to some other code hosting service such as GitLab or BitBucket, or whether I will host my own server (and if so, which server software I will use), or whether I will go bare-bones and just have plain Git repositories and home pages for each project. I'm also wondering if this might be a good time to move away from Git and give Fossil a try.
I also may keep my GitHub account (assuming they don't make radical changes to the terms of service or the nature of the service), so I can open and comment on issues of projects still hosted there, and so I can point to whatever new place I decide to host my stuff on in my profile.
~vbuaraujo será desativado, atualize seus links
2018-05-22 18:24 -0300. Tags: about, em-portugues
Leitouros e leitouras,
Assim como eu me livrei da UFRGS, a UFRGS se livrou de mim, e nas próximas semanas a minha página pessoal antiga (inf.ufrgs.br/~vbuaraujo) deixará de funcionar.
Peço humildemente àqueles que têm links para este blog que os atualizem para o endereço atual (https://elmord.org/blog/).
Meu e-mail da INF seguirá funcionando (ou assim me hão prometido).
Awey.
Bypassing Android's Factory Reset Protection on an Asus ZenFone Go
2018-05-15 00:03 -0300. Tags: comp, android, in-english
Modern Android versions come with a security (?) mechanism which requires the user to log in with a Google account previously used on the phone after a factory reset.
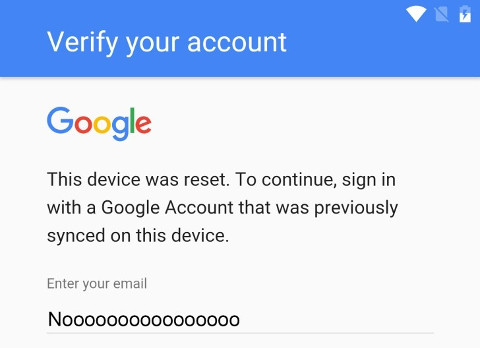
Picture source: Softpedia
There are dozens of different instructions for how to bypass this protection on the web, but none of the ones I tried to follow worked on the phone in question, an Asus ZenFone Go (ZB452KG). There are probably multiple firmware versions around for this phone model alone, so what works on one phone may not work on another. However, the various tutorials I found helped me discover a method that did work on my phone.
Ingredients: You will need a non-Google e-mail account to add to the phone, as well as the IMAP and STMP settings for your e-mail provider. You can remove this account after we're finished.
The goal: The goal of this exercise is to disable the Google apps in the phone settings: if they are disabled, the setup wizard will skip the account validation step. The trick is how to get to the phone settings before unlocking it.
Steps:
Follow the setup wizard until you get to the account validation screen. I recommend that, at the beginning of the wizard, you choose English as language, so that the Google app names all begin with "Google" and so are listed all together and are easier to find.
Select the e-mail field to open up the keyboard, tap the "⋮" button, select "Share", and "GMail".
Click "Skip" at the initial GMail screen. GMail will ask you to add an account. Configure your non-Google account here.
When you get to the compose message screen, tap the "⋮" button on the top right, choose "Settings", hit "⋮" again, and "Manage accounts". It will say "You're about to go to the Settings app …"; hit "Continue". Now we're at the phone settings!
Select "Apps", go to the "All" tab, and select the "Google Account Manager" app. Select "Force stop", and then "Disable". (You'll be asked to confirm these actions.)
Note: I actually disabled a bunch of other apps with names beginning with "Google" (such as "Google Services Framework") when I did this; I think this is not strictly necessary, but you can try it if disabling just "Google Account Manager" does not work.
Go back to the beginning of the setup wizard and follow the normal setup steps. Now at the point it would ask you for a Google account, it should ask for your name and surname instead. If this happens, it worked! Just finish the wizard and you'll have your phone unlocked.
If it does not work, try to go to "Settings > Apps > All" again and force stop the "Setup Wizard" applications (there are two of them on my phone), and then try to restart the wizard (you may have to turn your phone off and on again for that).
If you wish, go back to Settings and re-enable the apps you disabled. You can now also remove your IMAP e-mail account if desired.
Doing web stuff with Guile
2018-02-19 22:35 -0300. Tags: comp, prog, lisp, scheme, web, in-english
A few days ago I started working on Parenthetical Blognir, a rewrite of Blognir in Guile Scheme. In this post I'd like to talk a bit about some things I learned in the process.
Interactive development
I did the development using Geiser, an Emacs package for interactive Scheme development. It can connect with a running Scheme, and you can evaluate code from within Emacs, have completion based on the currently available bindings, etc.
The coolest part of this is being able to reevaluate function and class definitions while the program is running, and seeing the effects immediately. In this sense, GOOPS (the Guile Object Oriented Programming System, inspired by the Common Lisp Object System) is really cool in that you can redefine a class and the existing instances will automatically be updated to reflect the new class definitions (unlike, say, Python, in which if you redefine a class, it's an entirely new class, and instances of the old class will have no relationship with the new class).
One thing I realized is that you have to adapt your program a bit if you want to make the most of interactive development. For example, in Guile's web framework, there is a procedure (run-server handler), which starts up the web server and calls handler to serve each request. My request handler was a procedure named handle-request, so my code called (run-server handle-request). The problem is that this way run-server will be called with the value of handle-request at the time we started the server, and subsequent redefinitions of handle-request while the server is running will have no effect on the running server. Instead, I ended up writing something like:
(start-server (lambda (request body)
(handle-request request body)))
I.e., instead of calling handle-request directly, the server will call the anonymous function which, when called, will call handle-request. In this way, it will use the value of handle-request at each time the anonymous function is called, so it will see changes to the definition.
Another thing to take into account is that there may be some bindings you don't want to redefine when you reload a module, e.g., variables holding program state (in my case, a variable holding the blog object). For that, Guile provides a define-once form, which only defines a variable if it doesn't already exist.
One gotcha I encountered was when using parameters, the Scheme world equivalent of dynamically-scoped variables. Parameters in Guile have per-thread independent values, and since the web server and the REPL run in different threads, they may see different values for the same parameter. I ended up not using parameters anyway for other reasons (more on that later).
(web server)
Guile comes with a web framework of sorts, though it is pretty bare-bones. (Actually the main thing I missed in it was having to parse the request query and POST data by hand. At least it does provide a function to percent-decode URL components.) It has a philosophy of pre-parsing all headers into structured data types as a way of avoiding programming errors. It's an interesting idea; I have mixed feelings about it, but I think it's a valid idea to build a framework on (after all, if you're going the trouble of making a new framework, you might as well try some new ideas rather than creating yet another run-of-the-mill web framework).
You start the server by calling run-server with a callback (as mentioned above). Whenever a new request comes, the callback will be called with a request object and the request body as a bytevector. The callback must return (at least1) two values: a response object and a response body. Guile allows some shortcuts to be taken: Instead of a response object, you can pass an association list of response headers and the framework will automatically make a response object out of it. The response body may be either a string (which will be automatically encoded to the proper encoding, usually UTF-8), a bytevector, or a procedure; in the latter case, the procedure will be invoked with a port as an argument, and whatever you print to that port will be sent as the response body.
Rendering HTML
Guile comes with support for SXML, an S-expression based tree representation of XML. This means you can write things like:
(sxml->xml `(div (@ (class "foo"))
"Hello, world"))
and it will emit <div class="foo">Hello, world</div>. The nice thing is that strings appearing in the tree will be automatically escaped approprietely, so you don't have to worry about escaping (or forgetting to escape) data that may contain special characters, such as <, > or &.
That very feature was at first what led me not to want to use SXML, appealing though it was, to render Blognir pages. The reason is that post contents in Blognir come raw from a post file; I didn't want to parse the file HTML contents into SXML just to dump it again as HTML in the output2, and I saw no way to insert a raw string in the middle of an SXML tree bypassing the escaping in the output. So I began this adventure by printing chunks of HTML by hand. At some points I needed to escape strings to insert them in the HTML, so I wrote a small wrapper function to call sxml->xml on a single string and return the escaped string (by default sxml->xml prints to a port rather than returning a string).
When I got to the post comments form, where I have to do a lot of escaping (because all field values have to be escaped), I decided to use sxml->xml for once, for the whole form, rather than escaping the individual strings. I found it so nice to use that I decided to look up the source code for sxml->xml to see if there wasn't a way to insert raw data in the SXML tree without escaping, so I could use it for the whole page, not just the form. And sure enough, I found out that if you put a procedure in the tree, sxml->xml will call that procedure and whatever it prints is emitted raw in the result. This feature does not seem to be documented anywhere. (In fact, the SXML overview Info page says (This section needs to be written; volunteers welcome.). Maybe that's up to me!) By that point I had already written most of the rest of the page by printing HTML chunks, and I did not go back and change everything to use SXML, but I would like to do so. I did use SXML afterwards for generating the RSS feeds though, with much rejoicing.
Parameters – or maybe not
Parameters are used for dynamically scoped values. They are used like this:
;; 23 is the initial value of the parameter. (define current-value (make-parameter 23)) (define (print-value) (display (current-value)) (newline)) (print-value) ;; prints 23 (parameterize ([current-value 42]) (print-value)) ;; prints 42 (print-value) ;; prints 23 again
My original plan was to create a bunch of parameters for holding information about the current request (current-query, current-post-data and the like), so I wouldn't have to pass them as arguments to every helper request handling function; I would just bind the parameters at the main handle-request function, and all functions called from handle-request would be able to see the parameterized values.
The problem with my plan is that instead of returning the response body as a string from handle-request, I was returning a procedure for the web framework to call. By the time the procedure was called, handle-request had already finished, and the parameterize form was not in effect anymore. Therefore the procedure saw the parameters with their initial value rather than the value they had when the procedure was created. Oops!
Because closures don't close over their dynamic scope (that's kinda the whole point of dynamic scope), parameters ended up not being very useful for me in this case. I just passed everything as, ahem, parameters (the conventional kind) to the subfunctions.
Performance tuning
Despite its crude design, the original Blognir is pretty fast; it takes around 1.7ms to generate the front page in my home machine. I got Parenthetical Blognir at around 3.3ms for now. I'm sure there are still optimizations that can be done, and I may still try some things out, but right now I don't have any pressing need to make things faster than that.
I did learn a few things about optimizing Guile programs in the process, though. I used the ab utility (package apache2-utils on Debian) to measure response times, and Guile's statistical profiler to see where the bottlenecks were. I did not keep notes on how much impact each change I did had on performance (and in many cases I changed multiple things at the same time, so I don't know the exact impact of each change), but I can summarize some of the things I learned.
This is standard advice and applies to every programming language, but do use the profiler to find out performance bottlenecks. They often come from unexpected places, and it is far better to see the numbers than trying to guess where the bottlenecks might be.
Some things are slow because they take up CPU themselves, and some things are slow because they generate garbage, so your program spends more time in the garbage collector. The procedure currently taking the most time in Parenthetical Blognir is
%after-gc-thunk, and I still have not analysed it more carefully to determine where this is coming from.Guile has two versions of
format(the Guile counterpart toprintf): one from the(ice-9 format)module, written in Scheme, which supports various format specifiers; and a bare-bones one, written in C, available under the namesimple-format, which only supports the~aand~sformat specifiers with no qualifiers.3simple-formatis much faster than theformatfrom(ice-9 format), so if you only need the bare~aand~sformats and your program makes heavy use of them, I recommend usingsimple-format.My program was spending quite a bit of time on
read-stringto read post contents. It only reads the contents of a post to dump it into the response, andread-stringwill waste some time decoding the input from UTF-8 to Guile's internal string type, dynamically growing a string to the right size to fit the post contents, just to immediately decode it back to UTF-8 and discard the string as garbage. I found it more efficient to write a little function which takes two ports (the open post file and the open response port) and just copy the raw bytes in fixed-size chunks from one port to the other:(use-modules (rnrs bytevectors) (ice-9 binary-ports)) (define (pump-port in-port out-port) (let ([buffer (make-bytevector 65536)]) (let loop () (let ([count (get-bytevector-n! in-port buffer 0 65536)]) (when (not (eof-object? count)) (put-bytevector out-port buffer 0 count) (loop))))))For extra garbage reduction, you can reuse the buffer across calls (but be careful if the code may be called from multiple threads).
Conclusion
In general, I liked the experience of rewriting the blog in Guile. It was the first time I did interactive Scheme development with Emacs (previously I had only used the REPL directly), and it was pretty cool. Some things could be better, but I see this more as an opportunity to improve things (whether by contributing to existing projects, by writing libraries to make some things easier, or just as things to take into account if/when I decide to have a go again at trying to make my own Lisp), rather than reason for complaining.
There are still a few features missing from the new blog system for feature parity with the current one, but it already handles all the important stuff (posts, comments, list of recent comments, filtering by tag, RSS feeds). I hope to be able to replace the current system with the new one Real Soon Now™.
_____
1
If you return more than two values, the extra values will be passed back to the callback as arguments on the next call. You can use it to keep server state. If you want to use this feature, you can also specify in the call to run-server the initial state arguments to be passed in the first call to the callback.
2
And my posts are not valid XML anyway; I don't close my <p> tags when writing running text, for instance.
3
There is also a format binding in the standard environment. It may point to either simple-format or the (ice-9 format) format, depending on whether (ice-9 format) has been loaded or not.
Managing windows and taking notes from Emacs
2018-02-14 00:02 -0200. Tags: comp, emacs, in-english
EXWM and Org mode are two entirely unrelated pieces of Emacs software. However, by virtue of both running in Emacs, they can be combined in some interesting ways.
EXWM
EXWM is a window manager written in Emacs Lisp. I think this is the craziest thing I've seen written in Emacs Lisp so far, and yet it moves. It basically turns Emacs into a tiling window manager. Your windows become Emacs buffers, and you can manage them with the usual Emacs commands for splitting windows, changing focus, switching buffers, and so on. (I learned about it here.)
As a window manager, I don't think it does anything very interesting compared to other tiling window managers. Its real power comes from being integrated into Emacs. This means I can always use Emacs commands no matter what window I am in (for example, if I want to open a file, I can hit C-x C-f no matter what program currently has focus).
This also means it can be customized and scripted in Emacs Lisp. For example, one thing I did with it is make it display "urgent" windows (those that would usually blink in the taskbar) in my Emacs mode line. So far, that's not very interesting, because with a conventional desktop environment I would already have windows highlighted in the taskbar. But what I have also done is customize it so that some windows are detected as "urgent" even though they don't set the urgency window manager hint. For example, I have windows with titles like (1) Skype (i.e., windows with unread messages) tagged as urgent as well.
Another nice trick you can do with EXWM is send fake keypresses to windows. For example, one thing I did was to make a variant of Emacs' insert-char command (which allows entering characters by their Unicode name or hex codepoint) which can be called from any window, by asking for the character name, putting it into the clipboard, and then sending a fake C-v to the application.
My EXWM config file is here. It has grown a bit complex, and some things are still a bit kludgy/glitchy, but I've been using it for some 3-4 months for now. Take the parts you like from it.
Org-capture
Org is an Emacs mode for managing structured data in plain-text format, though that description doesn't really do justice to the thing. It can manage to-do lists, agendas, handle tables in awesome ways, and many more things. It can also export files to various formats, including Beamer presentations, which I've written about before. I'm still learning how to use it and all of its features, and I'm trying to use it for more things, including blogging. (I wrote some kludgy code to export Org files to blog posts, but I found out afterwards that it would be better to create a new export backend inheriting from the built-in HTML export backend. Still have to learn more about this though.)
One cool feature of Org mode is org-capture, a command for taking notes with little flow interruption from what you are currently doing. Once you have it all configured, you can hit something like C-c c j to create an entry using the journal template. The entry will be pre-filled according to the template, and can include, for example, a link to the place you called the command from. For example, if you call it from a w3m buffer, the new note will contain a link to the web page you were visiting. If you call it from some source code, it will create a link to the place you were in the source code file. Org can recognize a variety of different buffer types, and create links appropriate to the context you called it from. You can easily make it recognize new kinds of context by defining new functions and adding them to org-store-link-functions.
Combining the two things
The most immediately observable advantage of using Org-capture in conjunction with EXWM is that you can call it from anywhere, not just regular Emacs buffers, because now Emacs commands work from any window. No matter whether you are seeing a file or reading something in Firefox, you can just type C-c c j to take a note. I find this really nice.
Another advantage is that because you can add new functions to org-store-link-functions, and all your windows are now Emacs buffers, you can actually make org-capture recognize the context of non-Emacs windows too. This is especially useful for browser windows: you can make the link inserted in the note reflect the page you are visiting. Although I'm not aware of a clean way to extract the current URL from a browser window, you can make do by faking the keypresses of C-l (to select the address bar) followed by C-c (to copy the contents to the clipboard), and then reading the clipboard contents from Emacs. Like this:
;; Grab address from the browser.
(defun elmord-exwm-get-firefox-url ()
(exwm-input--fake-key ?\C-l)
(sleep-for 0.05) ; Wait a bit for the browser to respond.
(exwm-input--fake-key ?\C-c)
(sleep-for 0.05)
(gui-backend-get-selection 'CLIPBOARD 'STRING))
;; org-store-link functions must either return nil (if they don't recognize
;; the context), or call `org-store-link-props' with the appropriate link
;; properties and return non-nil.
(defun elmord-exwm-org-store-link ()
(when (and (equal major-mode 'exwm-mode)
(member exwm-class-name '("Firefox" "Firefox-esr")))
(org-store-link-props
:type "http"
:link (elmord-exwm-get-firefox-url)
:description exwm-title))) ; Use window title as link description.
;; Finally, we add the new function to the list of known store-link functions.
(add-to-list 'org-store-link-functions 'elmord-exwm-org-store-link)
I find this really cool.
That's all, folks
I have more things I'd like to write about Emacs, but that's it for now.
(finish-output mestrado)
2018-01-30 22:27 -0200. Tags: life, academia, mestrado, em-portugues
Gandalf: "Excellent work, Frodo. You defeated Sauron and now... hm! Now everyone can have happy lives forever. Thanks to you."
Frodo: "I know. I just wish... I could forget."
Leitouros e leitouras,
Pous que o infindável mestrado findou-se. Ainda falta a homologação da secretaria e da comissão da pós (e é por isso que é um finish-output e não um close), mas, tendo recebido o joinha da banca, orientadores e biblioteca, creio que só o que me resta agora é começar a rodar o garbage collector mental para desentupir o cérebro, e fazer a dança da vitória.
A monografia, para quem (insanamente) quiser ver, está aqui.
Resolução de ano novo
2018-01-01 22:55 -0200. Tags: life, mind, about, em-portugues
Eu não sou muito fã de resoluções de ano novo, por uma variedade de motivos, mas como resolução tentativa de ano novo eu escolho a seguinte:
Preocupar-se com as coisas que importam, e não se preocupar com as coisas que não importam.
Obviamente, o que importa e o que não importa é inteiramente subjetivo. Mas isso não importa.
Desejo a todos um feliz ano novo, e espero em breve voltar a escrever mais por aqui.
Impressions on R7RS-small: libraries, records, exceptions
2017-10-03 15:10 -0300. Tags: comp, prog, lisp, scheme, in-english
In the last post, I wrote a little bit about the historical context in which R7RS came about. In this post, I will comment on my impressions about specific features of the R7RS-small language.
First of all, I'd like to note that if you are going to read the R7RS-small report, you should also read the unofficial errata. As I read the document I spotted a few other errors not mentioned in the errata, but unfortunately I did not keep notes as I was reading. I'm not sure why a, um, revised version of the report is not published with the known errors corrected (a Revised7.01 Report?), but alas, it isn't, so that's something to keep in mind.
In this post, I will talk mainly about the differences between R5RS and R7RS-small, since R7RS-small is more of an incremental extension of R5RS, rather than R6RS. This is not intended as a complete or exhaustive description of each feature; for that, consult the report.
Libraries/modules
R7RS introduced the concept of libraries (what some other systems call modules; I suppose R6RS and R7RS chose the name "library" to avoid conflict with the concept of modules in existing implementations). Library names are lists of symbols and non-negative integers, such as (scheme base), or (srfi 69). A library has a set of imports, a set of exported symbols, and code that constitutes the library. A library definition looks like this:
(define-library (foo bar)
(import (scheme base)
(scheme write))
(export hello)
(begin
(define (hello)
(display "Hello, world!\n"))))
Instead of putting the library code directly in the define-library form (inside a begin clause), it is also possible to include code from a different file with the (include "filename") directive (or include-ci for parsing the file case-insensitively; standard Scheme was case-insensitive until R5RS (inclusive)). This makes it easier to package R5RS code as an R7RS library, by including the older code within a library declaration. It's also a way to avoid writing all library code with two levels of indentation.
Imports can be specified or modified in a number of ways:
- One can import a whole library: (import (scheme base))
- Or just some identifiers from it: (import (only (some lib) someid1 someid2))
- Or all but some identifiers: (import (except (some lib) unwanted-id1 unwanted-id2))
- Or rename some identifiers: (import (rename (some lib) (original1 new1) (original2 new2)))
- Or add a prefix to all identifiers: (import (prefix (some lib) somelib/))
These forms can be combined (e.g., you can import only some identifiers and add a prefix to them).
Exports just list all identifiers to be exported, but you can also write (rename internal-name exported-name) to export identifiers with a different name than they have within the library body.
Unlike R6RS, all library code directly embedded in the define-library form must be written within a begin clause. At first I found this kinda weird, but it has an interesting consequence: the library definition sublanguage does not have to know anything about the rest of the programming language. There is only a limited number of kinds of subforms that can appear within define-library, and parsing it does not require knowing about the values of any identifiers. This means that define-library can be more easily processed as data. One can imagine useful tools which read library definitions from files and, say, compute the dependencies of a program, among other possibilities.
In fact, R7RS does not classify define-library or its subforms as syntax forms, i.e., they are something apart from Scheme expressions. This also resolves a problem that would occur if define-library were an expression. The report specifies that the initial environment of a program is empty. So, how would I use import declarations before importing the library where import declaration syntax is defined? Of course one way around this would be to make (scheme base) available by default rather than start with the empty environment. But the solution adopted by R7RS means we don't have to import (scheme base) if we don't want to (for example, if we want to import (scheme r5rs) instead to package R5RS code as an R7RS library). (The report does define for convenience some procedures and syntax forms with the same name as corresponding library subforms, e.g., include.)
R7RS also standardized cond-expand (extended from SRFI 0). cond-expand is a mechanism somewhat like ifdefs in C for conditionally including code depending on whether the implementation defines specific feature symbols, or whether some library is available. This makes it possible to provide different implementations of a procedure (or a whole library) depending on the current implementation. One way we could use it is to write shims, or compatibility layer libraries to provide an uniform interface for features that are implemented differently by various implementations. For example, in Common Lisp, many implementations support threads, but they provide different interfaces. Bordeaux Threads is a library which provides a uniform API and maps those to the corresponding functions in each implementation it supports. Now we can do similar things in R7RS for those features that are supported everywhere but in incompatible ways (e.g., for networking).
Libraries and cond-expand are by far the most important addition in R7RS relative to R5RS. Even if we did not have any of the other features, we could package them as libraries and provide implementation-specific code for them via cond-expand.
Missing things
The report does not specify a mapping between library names and file names. I realize that it would be kinda hard to make everyone agree on this, but it is somewhat of a hurdle in distributing programs organized into libraries. Some implementations, such as Chibi, will look up a library named (foo bar) in a file named foo/bar.sld (where .sld stands for Scheme library definition), whereas CHICKEN will look it up at foo.bar.*. There is a project of a portable package manager for R7RS called Snow, which I think takes care of mapping packaged library files to implementation-specific names, but I haven't taken the time to check it out yet.
R7RS takes the excellent step of specifying that library names whose first component is the symbol srfi are reserved for implementing SRFIs, but then fails to specify how to name a specific SRFI. In practice, the few implementations I checked all agree on using (srfi n) as the name of the library implementing SRFI number n (i.e., I can write (import (srfi 69)) and remain reasonably portable), so this may turn out not to be a problem in practice.
Records
R7RS incorporates the define-record-type form from SRFI 9, for defining new record/struct types. It is a somewhat verbose form, which requires specifying the record constructor arguments and the names for each field accessor/getter and (optional) mutator/setter, but it's basically the least common denominator that any implementation which has some form of records can easily support. It looks like this:
(define-record-type <person> (make-person name age) person? (name person-name person-name-set!) (age person-age person-age-set!))
Here:
- <person> is the record type name. R7RS-small does not specify any particular use for this name, but R7RS-large or some other SRFI may specify uses for it (e.g., to allow querying information about the record type).
- (make-person name age) defines the constructor procedure and order of arguments for this record.
- person? defines the name of a predicate which will answer true when given records created with make-person, and false for other Scheme values.
- The clause (name person-name person-name-set!) declares a field called name, associated with a getter procedure person-name to extract the name field from a given person record, and a setter procedure person-name-set! for mutating the name field in a person record. The next clause does the same for the field age.
R5RS did not have any way to define new types disjunct from existing types. R6RS provides a more complex records facility, including both a syntactic and a procedural layer allowing reflection, but I don't know it well enough to comment. (I have read some comments on problems in the interaction between syntactically- and procedually-defined records, but I don't know the nature of the problems or how serious they are.)
Missing things
Reflection would be nice, or at least a way to convert a record into a vector or something like this (though I realize this might displease some people), but we could make libraries for that. Another thing that would be nice is for records to have a standard printed representation which could be printed out and read back again, but I realize there is a slightly complicated interaction here with the module system (the printed representation should be tagged with the record type in a way that will work regardless of which module it is read back in), and this might not even be desirable for implementation-internal types which happen to be defined in terms of define-record-type.
Exceptions
R7RS incorporates the exception handling mechanisms from R6RS, but not the condition types. Any value can be raised in an exception. The raise procedure raises a value as an exception object, or condition, to be caught by an exception handler. The guard form can be used to install an exception handler to be active during the evaluation of its body. The guard form names a variable to hold the captured condition, a sequence of cond-like clauses to determine what action to take given the condition, and a body to be executed. It looks like this:
(guard (err
((file-error? err) (display "Error opening file!\n"))
((read-error? err) (display "Error reading file!\n"))
(else (display "Some other error\n")))
(call-with-input-file "/etc/passwd"
(lambda (file)
(read-line file))))
If an else clause is not provided and no other clause of the guard form matches, the exception propagates up the stack until some handler catches it. If an exception is raised and caught by a guard clause, the value returned by the guard form is whatever is returned by the body of that clause.
Beside raise, R7RS also defines a procedure (error message irritants...), which raises an error object (satisfying the error-object? predicate) encapsulating an error message and a sequence of objects somehow related to the error (called "irritants"). It also defines the procedures error-object-mesage and error-object-irritants to extract the components of the error object.
R7RS does not define specific object types to represent errors; it only says that objects satisfying a given predicate must be raised in some circumstances. An implementation might define a record type for that, or just use lists where the first element represents the error type, or whatever is appropriate for that implementation.
At first I did not think exceptions were that important in the grand scheme of things (heh), since you can implement them on the top of continuations. (And indeed, exceptions in R6RS are in a separate library rather than the base language, although this does not mean much in R6RS because, if I understand correctly, all libraries are mandatory for R6RS implementations.) However, I then realized that until R5RS (inclusive), there was no standard way to signal an error in Scheme code, and perhaps more importantly, no standard way of catching errors. If portable libraries are to become more prominent, we will need a standard way of signalling and catching errors across code from different projects, so exceptions are a good add-on.
Beside raise, R7RS also defines raise-continuable, which raises an exception but, if the guard exception handler returns, it returns to the point where the exception was raised rather than exiting from the guard handler form. [Correction: this is how raise-continuable interacts with with-exception-handler, not guard. I'm still figuring how guard acts with respect to continuable exceptions.] On the top of this, something like Common Lisp's restarts can be implemented.
One side effect of having guard in the language is that now you can do control flow escapes without using call-with-current-continuation (call/cc for short). In theory this could be more efficient than capturing the fully general continuation just to escape from it once; in practice, some implementations may rely on call/cc to implement guard (the example implementation provided in the report does), so this performance advantage may not realize. But just having a construct to express a one-shot escape is already great, because it allows expressing this intent in the program, and potentially allows implementations to emit more efficient code when a full continuation is not required.
I was wondering if one could implement unwind-protect (a.k.a. try/finally) in terms of guard, and so avoid dynamic-wind for error-handling situations. Alas, I don't think this is possible in general, because the presence of raise-continuable means an error handler may execute even though control may still return to the guard body. I wish to write more about continuations in a future post.
Conclusion
Libraries (plus cond-expand), records and exceptions are the most important additions in R7RS-small relative to R5RS, and they are all a great step towards enabling code reuse and portability across implementations, while not constraining Scheme implementors unnecessarily. I am particularly happy about libraries and cond-expand, because this means we can start writing compatibility libraries to bridge differences between implementations without having to rely on a standardization process.
I have some other comments to make on I/O, bytevectors, and other parts of the standard library, but they can wait for a future post.
R5RS, R6RS, R7RS
2017-10-01 22:11 -0300. Tags: comp, prog, lisp, scheme, in-english
Over the last few days I have skimmed over R7RS, the Revised⁷ Report on [the Algorithmic Language] Scheme. I thought I'd write up some of my impressions about it, but I decided first to write a bit about the history and the context in which R7RS came about and the differing opinions in the Scheme community about R6RS and R7RS. In a future post, I intend to write up about my impressions of specific features of the standard itself.
The Scheme language was first described in a document named the "Report on the Algorithmic Language Scheme". Afterwards, a second version, called the "Revised Report on the Algorithmic Language Scheme", came out. The following version of the standard was called the "Revised Revised Report …", or "Revised² Report …" for short. Subsequent versions have kept this naming tradition, and the abbreviation RnRS (for some n) is used to refer to each version of the standard.
Up to (and including) R5RS, all versions of the standard were ratified only by unanimous approval of the Scheme Steering Committee. As a result, each iteration of the standard was a conservative extension of the previous version. R5RS defines a very small language: the whole document is just 50 pages. The defined language is powerful and elegant, but it lacks many functions that are typically expected from the standard library of a modern language and necessary for many practical applications. As a result, each Scheme implementation extended the standard in various ways to provide those features, but they did so in incompatible ways with each other, which made it difficult to write programs portable across implementations.
To amend this situation a bit, the Scheme community came up with the Scheme Requests for Implementation (SRFI) process. SRFIs are somewhat like RFCs (or vaguely like Python's PEPs): they are a way to propose new individual features that can be adopted by the various implementations, in a way orthogonal to the RnRS standardization process. A large number of SRFIs have been proposed and approved, and some are more or less widely supported by the various implementations.
R6RS attempted to address the portability problem by defining a larger language than the previous reports. As part of this effort, the Steering Committee broke up with the tradition of requiring unanimous approval for ratification, instead requring a 60% majority of approval votes. R6RS defines a much larger language than R5RS. The report was split into a 90 page report on the language plus a 71 page report on standard libraries (plus non-normative appendices and a rationale document). The report was ratified with 67 yes votes (65.7%) and 35 no votes (34.3%).
The new report caused mixed feelings in the community. Some people welcomed the new standard, which defined a larger and more useful language than the minimalistic R5RS. Others felt that the report speficied too much, reinvented features in ways incompatible with existing SRFIs, and set some things in stone too prematurely, among other issues.
In response to this divide, the Scheme Steering Committee decided to split the standard into a small language, more in line with the minimalistic R5RS tradition, and a large language, intended to provide, well, a larger language standardizing a larger number of useful features. The R7RS-small report was completed in 2013. The R7RS-large process is still ongoing, being developed in a more incremental way rather than as one big thing to be designed at once.
I think that the R6RS/R7RS divide in part reflects not only differing views on the nature of the Scheme language, but also differing views on the role of the RnRS standards, the Steering Committee, and the SRFI process. In a discussion I read these days, a person was arguing that R6RS was a more useful standard to them, because for most practical applications they needed hashtables, which R6RS standardized but R7RS did not. My first thought was "why should hashtables be included in the standard, if they are already provided by SRFI 69?". This person probably does not consider SRFIs to be enough to standardize a feature; if something is to be portable across implementations, it should go in the RnRS standard. In my (current) view, the RnRS standard should be kept small, and SRFIs are the place to propose non-essential extensions to the language. My view may be colored by the fact that I started using Scheme "for real" with CHICKEN, an implementation which not only supports a large number of SRFIs, but embraces SRFIs as the way various features are provided. For example, whereas many implementations provide SRFI 69 alongside their own hashtable functions, CHICKEN provides SRFI 69 as the one way of using hashtables. So, CHICKEN users may be more used to regard SRFIs as a natural place to get language extensions from, whereas users of some other implementations may see SRFIs as something more abstract and less directly useful.
I have already expressed my view on Scheme's minimalism here, so it's probably no surprise that I like R7RS better than R6RS. I don't necessarily think R6RS is a bad language per se (and I still have to stop and read the whole R6RS report some day), I just have a preference for the standardized RnRS language to be kept small. (I'm okay with a larger standard a la R7RS-large, as long as it remains separate from the small language standard, or at least that the components of the large language remain separate and optional.) I also don't like every feature of R7RS-small, but overall I'm pretty satisfied with it.
On Scheme's minimalism
2017-09-14 19:34 -0300. Tags: comp, prog, lisp, scheme, pldesign, ramble, in-english
[This post started as a toot, but grew slightly larger than 500 characters.]
I just realized something about Scheme.
There are dozens, maybe hundreds, of Scheme implementations out there. It's probably one of the languages with the largest number of implementations. People write Schemes for fun, and/or to learn more about language implementations, or whatever. The thing is, if Scheme did not exist, those people would probably still be writing small Lisps, they would just not be Scheme. The fact that Scheme is so minimal means that the jump from implementing an ad-hoc small Lisp to implementing Scheme is not that much (continuations notwithstanding). So even though Scheme is so minimal that almost everything beyond the basics is different in each implementation, if there were not Scheme, those Lisps would probably still exist and not have even that core in common. From this perspective, Scheme's minimalism is its strength, and possibly one of the reasons it's still relevant today and not some forgotten Lisp dialect from the 1970s. It's also maybe one of the reasons R6RS, which departed from the minimalist philosophy, was so contentious.
Plus, that core is pretty powerful and well-designed. It spares each Lisp implementor from part of the work of designing a new language, by providing a solid basis (lexical scoping, proper closures, hygienic macros, etc.) from which to grow a Lisp. I'm not one hundred percent sold on the idea of first class continuations and multiple values as part of this core*, and I'm not arguing that every new Lisp created should be based on Scheme, but even if you are going to depart from that core, the core itself is a good starting point to depart from.
[* Though much of the async/coroutine stuff that is appearing in modern languages can be implemented on the top of continuations, so maybe their placement in that core is warranted.]
« Mais recentes / Newer posts | Mais antigos / Older posts »