On the Twitter shitshow
2022-12-18 19:49 +0000. Tags: comp, web, in-english
The day after Elon Musk finalized the acquisition of Twitter, I decided to stop using it and move definitively to Mastodon. I thought things would go downhill at Twitter, but honestly, I did not think they would go downhill so fast. Since then:
Musk fired half of the Twitter staff, and then tried to hire some of the people back after realizing he actually needed some of them.
We had the whole Twitter Blue fiasco, where the Twitter ‘verified’ checkmark, previously available only to public figures by verifying your identity with the Twitter staff, could now be obtained by anyone by buying a Twitter Blue subscription, with much hilarity ensuing.
Musk banned some accounts tracking the locations of billionaires’ private jets (obtained from publicly available information). Subsequently, he also banned a number of journalists that had published articles about the aforementioned ban. He also banned the Mastodon project’s account on Twitter, supposedly because it posted a tweet saying that some of the jet tracking accounts had moved to Mastodon.
The journalists’ and Mastodon’s accounts have been reinstated, but since then, Twitter has been blocking links to
mastodon.social(and many other instances). Attempts to tweet links to it yield an error with no explanation to the user: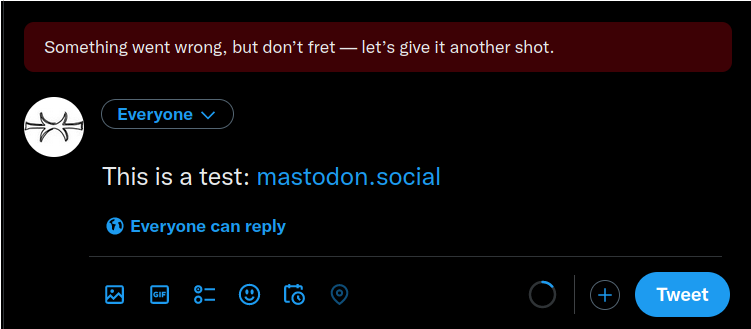
And attempts to follow an existing link yield to a page saying that the link ‘may be unsafe’:
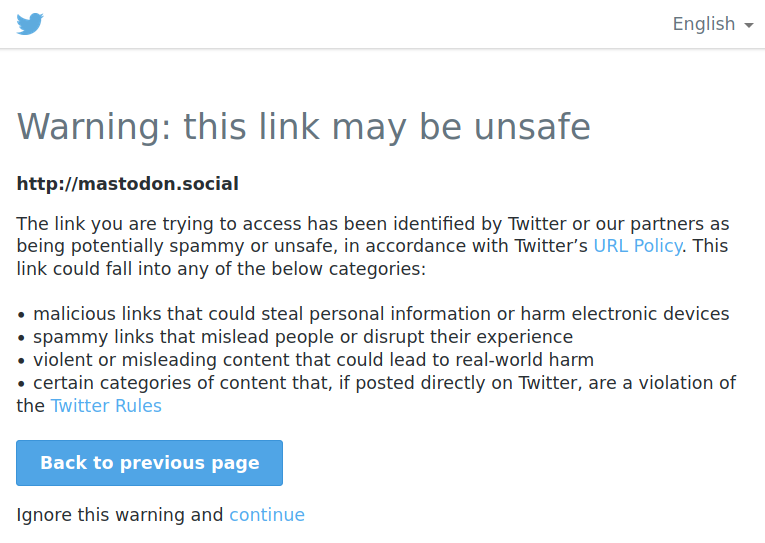
While writing this post, I found out that “promotion of alternative social platforms”, such as linking to your account on Mastodon, Instagram or Facebook, is now forbidden by Twitter policy. [Update (2022-12-19): That page has been deleted. You can see the WebArchive version.]
The banning of journalists for talking about things Elon does not like, and blocking of Mastodon links, should be a clear enough sign that (1) Twitter is entirely under the whims of its new owner, and (2) the guy has whims aplenty. This is not anymore a situation of “I will stop using this service because it will likely become crap in the future”, it’s a situation of “I cannot use this service anymore because it’s crap already”. If they follow through with their new policy, my account there (which currently only exists to point to my Mastodon one, and to keep the username from being taken) will soon probably be suspended through no effort of my own.
All of this is quite disturbing considering the reliance of journalists on Twitter. Mastodon is a nice place if your goal is to find people with common interests and have conversations with them, but for journalists, I think the main value of Twitter is finding out news about what is happening in the world, through trending topics, global search, and things going viral, none of which are things Mastodon is designed to provide or encourage (on the contrary, Mastodon is in many ways designed to avoid such features). Therefore, I don’t see journalists migrating en masse to Mastodon. However, begging the billionaire to not expel them from his playground is not a sustainable course of action in the long run (and even in the short run, judging by the speed of things so far). I’m curious about how things will roll out on that front.
Given all that, I won’t be posting to Twitter anymore, not even to announce new blog posts as I used to do. You can follow this blog via RSS feed as always, or follow me on Mastodon at @elmord@functional.cafe. (Maybe one day I will add an option to subscribe by e-mail, but that will require setting up an e-mail server, and so far I have not found the will to do that. And yes, it’s been almost a year since I last posted anything here, but this blog is not quite dead.)
Some thoughts on Gemini and the modern Web
2022-02-20 19:22 +0000. Tags: comp, web, ramble, in-english
The web! The web is too much.
Gemini is a lightweight protocol for hypertext navigation. According to its homepage:
Gemini is a new internet protocol which:
- Is heavier than gopher
- Is lighter than the web
- Will not replace either
- Strives for maximum power to weight ratio
- Takes user privacy very seriously
If you’re not familiar with Gopher, a very rough approximation would be navigating the Web using a text-mode browser such as lynx or w3m. A closer approximation would be GNU Info pages (either via the info utility or from within Emacs), or the Vim documentation: plain-text files with very light formatting, interspersed with lists of links to other files. Gemini is essentially that, except the files are remote.
Gemini is not much more than that. According to the project FAQ, “Gemini is a ‘less is more’ reaction against web browsers and servers becoming too complicated and too powerful.” It uses a dead-simple markup language called Gemtext that is much simpler than Markdown. It has no styling or fancy formatting, no client-side scripting, no cookies or anything that could be used for tracking clients. It is designed to be deliberately hard to extend in the future, to avoid such features from ever being introduced. For an enthusiastic overview of what it is about, you can check this summary by Drew DeVault.
I’m not that enthusiastic about it, but I can definitely see the appeal. I sometimes use w3m-mode in Emacs, and it can be a soothing experience to navigate web pages without all the clutter and distraction that usually comes with it. This is big enough of an issue that the major browsers implement a “reader mode” which attempt to eliminate all the clutter that accompanies your typical webpage. But reader mode does not work for all webpages, and won’t protect you from the ubiquitous surveillance that is the modern web.
I do most of my browsing on Firefox with uBlock Origin and NoScript on. Whenever I end up using a browser without those addons (e.g., because it’s a fresh installation, or because I’m using someone else’s computer), I’m horrified by the experience. uBlock is pretty much mandatory to be able to browse the web comfortably. Every once in a while I disable NoScript because I get tired of websites breaking and having to enable each JavaScript domain manually; I usually regret it within five minutes. I have a GreaseMonkey script to remove fixed navbars that websites insist on adding. Overall, the web as it exists today is quite user-inimical; addons like uBlock and NoScript are tools to make it behave a little more in your favor rather than against you. Even text-mode browsers like w3m send cookies and the Referer header by default, although you can configure it not to. Rather than finding and blocking each attack vector, a different approach would be to design a platform where such behaviors are not even possible. Gemini is such a platform.
The modern web is also a nightmare from an implementor side. The sheer size of modern web standards (which keep growing every year) mean that it’s pretty much out of question for a single person or a small team to write and maintain a new browser engine supporting modern standards from scratch. It would take years to do so, and by that time the standards would have already grown. This has practical consequences for users: it means the existing players face less competition. Consider that even Microsoft has given up on maintaining its own browser engine, basing modern versions of Edge on Chromium instead. Currently, three browser engines cover almost all of the browser market share: Blink (used by Chrome, Edge and others); WebKit (used by Safari, and keeping a reasonable portion of the market by virtue of being the only browser engine allowed by Apple in the iOS app store); and Gecko (used by Firefox, and the only one here that can claim to be a community-oriented project). All of these are open-source, but in practice forking any of them and keeping the fork up-to-date is a huge task, especially if you are forking because you don’t like the direction the mainstream project is going, so divergencies will accumulate. This has consequences, in that the biggest players can push the web in whatever direction they see fit. The case of Chrome is particularly problematic because it is maintained by Google, a company whose main source of revenue comes from targeted ads, and therefore has a vested interest in making surveillance possible; for instance, whereas Firefox and Safari have moved to blocking third-party cookies by default, Chrome doesn’t, and Google is researching alternatives to third-party cookies that still allow getting information about users (first with FLoC, now with Topics), whereas what users want is not to be tracked at all. The more the browser market share is concentrated in the hands of a few players, the more leeway those players have in pushing whatever their interests are at the expense of users. By contrast, Gemini is so simple one could write a simplistic but feature-complete browser for it in a couple of days.
Gemini is also appealing from the perspective of someone authoring a personal website. The format is so simple that there is not much ceremony in creating a new page; you can just open up a text editor and start writing text. There is no real need for a content management system or a static page generator if you don’t want to use one. Of course you can also keep static HTML pages manually, but there is still some ceremony in writing some HTML boilerplate, prefixing your paragraphs with <p> and so on. If you want your HTML pages to be readable in mobile clients, you also need to add at least the viewport meta tag so your page does not render in microscopic size. There is also an implicit expectation that a webpage should look ‘fancy’ and that you should add at least some styling to pages. In Gemini, there isn’t much style that can be controlled by authors, so you can focus on writing the content instead. This may sound limiting, but consider that most people nowadays write up their stuff in social media platforms that also don’t give users the possibility of fancy formatting, but rather handle the styling and presentation for them.
* * *
As much as I like this idea of a bare-bones, back-to-the-basics web, there is one piece of the (not so) modern Web that I miss in Gemini: the form. Now that may seem unexpected considering I have just extolled Gemini’s simplicity, and forms deviate quite a bit from the “bunch of simple hyperlinked text pages” paradigm. But forms do something quite interesting: they enable the Web to be read-write. Project such as collaborative wikis, forums, or blogs with comment sections require some way of allowing users to send data (other than just URLs) to the server, and forms are a quite convenient and flexible way to do that. Gemini does have a limited form of interactivity: the server may respond to a request with an “INPUT” response code which tells the user browser to prompt for a line of input, and then repeat the request with the user input appended as the query string in the URL (sort of like a HTTP GET request). This is meant to allow implementing pages such as search engines which prompt for a query to search, but you can only ask for a single line of input at a time this way, which feels like a quite arbitrary limitation. Forms allow an arbitrary number of fields to be inputted, and even arbitrary text via the <textarea> element, making them much more general-purpose.
Of course, this goes against the goal stated in the Gemini FAQ that “A basic but usable (not ultra-spartan) client should fit comfortably within 50 or so lines of code in a modern high-level language. Certainly not more than 100.” It also may open a can of worms, in that once you want to have forums, wikis or other pages that require some form of login, you will probably want some way to keep session state across pages, and then we need some form of cookies. Gemini actually already has the idea of client-side certificates which can be used for maintaining a session, so maybe that’s not really a problem.
As a side note, cookies (as in pieces of session state maintained by the client) don’t have to be bad, the web just happens to have a pretty problematic implementation of that idea, amplified by the fact that webpages can embed resources from third-party domains (such as images, iframes, scripts, etc.) that get loaded automatically when the page is loaded, and the requests to obtain those resources can carry cookies (third-party cookies). Blocking third-party cookies goes a long way to avoid this. Blocking all third-party resources from being loaded by default would be even better. Webpages would have to be designed differently to make this work, but honestly, it would probably be for the best. Alas, this ship has already sailed for the Web.
* * *
There are other interesting things I would like to comment on regarding Gemini and the Web, but this blog post has been lying around unfinished for weeks already, and I’m too tired to finish it at the moment, so that’s all for now, folks.
The curious case of NFC and LineageOS battery consumption
2021-05-31 21:30 +0100. Tags: comp, android, in-english
I was experiencing short battery duration (the battery was lasting barely 1 day) on my Samsung Galaxy J3 (2016) phone running LineageOS 14.1. The battery didn’t last any longer with the original ROM, so I assumed that the battery was old and bought a new one, replacing the original 2600mAh battery with an third-party 3630mAh one. The battery duration did improve a bit, but not nearly as much as I expected it to with a new battery with larger capacity. So I decided to investigate the situation a bit better.
The webs had told that the problem was likely some application holding a wakelock, blocking the phone from sleeping. I installed an app called BetterBatteryStats, which can be found on F-Droid. This app runs in background and collects battery usage statistics from running apps; you have to let it run for a while to get useful information from it. After some 30 minutes, I looked at the Partial Wakelocks panel and saw that there was a NfcService:mRoutingWakeLock item responsible for some 22% of battery consumption.
Now, NFC is a technology used for contactless payments using the phone, and similar applications. The Galaxy J3 does not support NFC. I’m not sure why the system was wasting CPU on this; I have found other people complaining about this same issue on the same ROM and phone.
The solution is to disable NFC Service in the system. Open up adb shell, become root (su), and then run:
pm hide com.android.nfc
After you do this, the system will loop complaining that NFC Service has been stopped. Restart the phone, and the error will be gone.
After a full charge, the system battery stats now tell me the battery will last 4 days. Will it really? Only time will tell, but I can already see that the battery is draining much more slowly than before.
Lenovo L22e-20 screen brightness and XRandR mode
2021-02-07 12:41 +0000. Tags: comp, unix, x11, in-english
Computer screens are a complicated business for me: most screens are too bright for my eyes even at the zero brightness setting. I have had some luck with the most recent laptops I used, though – a Dell Latitude 7490 I bought second-hand last year, and an HP Pavillion Gaming Laptop provided by my company, both of which have excellent screens – so I wondered if maybe monitor technology had improved enough lately that I would be able to get an external monitor that won’t burn my eyes after a few hours use. So I decided to try my luck with a Lenovo L22e-20 monitor.
When it arrived, I tried it out and was immediately disappointed. It was just as bad brightness-wise as every other LCD external monitor I had used. Even at the zero brightness setting, the black background was not black, but dark grey, which made the contrast too low. The image quality was really good for watching videos, but for staring at text for extended periods of time, it was just not comfortable to look at; my laptop screen was much better. I was so disappointed that I decided I would return the monitor and order a different one.
A couple of days later, I decided to try it again, and to my great surprise, the monitor did not look bad at all. The black was really black, the brightness was pretty good (though I wish I could lower it a little bit further at night). I wondered if I had just gotten used to the new monitor, but the difference was so great that it was hard to believe it was just a psychological effect.
A few hours later, I wanted to see how i3 would handle workspaces when screens are disconnected or connected to a running session. So I disconnected the Lenovo monitor and connected it again – and to my even greater surprise the screen came back with the awful brightness of the first time. I tried to look at every setting in the monitor, but nothing had changed; I tried disconnecting and connecting again, to no avail; I tried to turn everything off and on again – nothing changed, same awful brightness.
The next day, I decided to look at XRandR settings – maybe it was some software-side gamma or brightness setting or something that was affecting the brightness. I ran xrandr --verbose, and gamma/brightness values were normal, but I noticed something else: there were five different 1920x1080 modes for the screen. This is the relevant part of the output:
1920x1080 (0xa4) 148.500MHz +HSync +VSync *current +preferred
h: width 1920 start 2008 end 2052 total 2200 skew 0 clock 67.50KHz
v: height 1080 start 1084 end 1089 total 1125 clock 60.00Hz
1920x1080 (0xa5) 174.500MHz +HSync -VSync
h: width 1920 start 1968 end 2000 total 2080 skew 0 clock 83.89KHz
v: height 1080 start 1083 end 1088 total 1119 clock 74.97Hz
1920x1080 (0xa6) 148.500MHz +HSync +VSync
h: width 1920 start 2008 end 2052 total 2200 skew 0 clock 67.50KHz
v: height 1080 start 1084 end 1089 total 1125 clock 60.00Hz
1920x1080 (0xa7) 148.500MHz +HSync +VSync
h: width 1920 start 2448 end 2492 total 2640 skew 0 clock 56.25KHz
v: height 1080 start 1084 end 1089 total 1125 clock 50.00Hz
1920x1080 (0xa8) 148.352MHz +HSync +VSync
h: width 1920 start 2008 end 2052 total 2200 skew 0 clock 67.43KHz
v: height 1080 start 1084 end 1089 total 1125 clock 59.94Hz
Here, besides the resolution, frequencies, and other characteristics, each mode is identified by a hexadecimal code in parentheses (0xa4, 0xa5, etc.). Turns out you can pass those codes to the xrandr --mode option instead of a resolution such as 1920x1080 to select one among multiple modes with the same resolution.
I decided to try the other modes, just to see what difference it would make – and lo and behold, the second mode made the screen brightness good again! All the other modes left the screen with the bright background. I don’t know what it is specifically about this mode that had an effect on brightness, but I notice two things: it is the mode with the highest frequency, and it is the only one with -VSync rather than +VSync (the xorg.conf manpage tells us this is the polarity of the VSync signal, whatever that is). Maybe one (or both) of these elements is involved in the trick.
Actually, even if you run xrandr without the --verbose option, it will list potentially multiple modes for each resolution, by showing all available refresh rates for each resolution:
HDMI-1 connected 1920x1080+0+0 (normal left inverted right x axis y axis) 476mm x 268mm 1920x1080 60.00 + 74.97* 60.00 50.00 59.94 1920x1080i 60.00 50.00 59.94 1680x1050 59.88 1280x1024 75.02 70.00 60.02 1440x900 59.90 1152x864 75.00 1280x720 60.00 60.00 50.00 59.94 1024x768 75.03 70.07 60.00 800x600 72.19 75.00 60.32 720x576 50.00 50.00 50.00 720x480 60.00 60.00 59.94 59.94 59.94 640x480 75.00 72.81 60.00 59.94 59.94 720x400 70.08
I had never paid much attention to this, but you can actually select the specific mode you want by calling, for example, xrandr --output HDMI-1 --mode 1920x1080 --rate 74.97, specifying both the resolution and the refresh rate. In some cases, though, there are multiple modes with the same refresh rate (for example, the 720x576 line above has three different modes with the same refresh rate 50.00); in this case, I think the only way to choose a specific mode is to specify the hexadecimal code of the mode listed by the --verbose option.
If you don’t specify a refresh rate or give a specific mode hex code, XRandR will theoretically select the “preferred” mode, which is the one with a + sign after it in the output. For this Lenovo monitor, the preferred mode is a bad one, so you have to override it with these options.
The weirdest thing about this story is that, on the day the monitor was suddenly good, Xorg had apparently selected a non-preferred mode by pure chance for some reason. If that had not happened, I would probably have never discovered that the monitor had a good mode at all.
Some impressions about Go
2020-12-13 10:06 +0000. Tags: comp, prog, golang, in-english
A couple of months ago, I decided to rewrite the implementation of Fenius from scratch… in Go. I’ve also been working on a web project in Go at work. In this post, I write some of my reflections about the language.
First, a bit of a disclaimer. This post may end up sounding too negative; yet I chose to write the implementation of Fenius in Go for a reason, and I don’t regret this decision. Therefore, despite all the complaints I have about the language, I still think it’s a useful tool to have in my toolbox. With that in mind, here we go.
Also, a bit of context for those who don’t follow this blog regularly: Fenius is a programming language I am designing and playing with in my free time. The goal is to mix elements of functional and object-oriented programming and Lisp-style macros in a non-Lisp syntax, among other things. In its current incarnation, the language is implemented as an interpreter in written Go.
Why did I choose Go for this project?
I’ve been curious about Go for a long time, but had never taken the time to play with it. I don’t have much patience for following tutorials, so for me the most effective way of learning a new programming language is to pick some project and try to code it in the language, and learn things as I go.
I realized Fenius would be a good match for Go for a bunch of reasons:
Compared to higher-level languages (such as Common Lisp):
Go generates small, self-contained executables; the end-user does not have to have Go installed to run the Fenius binary. SBCL can do that too, but the resulting binary is much larger.
It is easy to generate Go binaries for multiple platforms, without having to run the compiler in those platforms as well.
The Go string type is essentially just an array of bytes that is treated as UTF-8 encoded data by the language, but has no qualms dealing with invalid UTF-8 data. This happens to mostly match the semantics of strings in Fenius, and is in contrast with languages such as Common Lisp, Scheme or Python which try to encode strings coming from the outside world as Unicode strings (including file names and program arguments, which have no guarantee of being valid UTF-8, with Python doing some tricks to smuggle arbitrary bytes into a Unicode string).
(The only point where Go and Fenius diverge is that, when handling strings as UTF-8, Go generally replaces invalid bytes in the input with the Unicode replacement character (U+FFFD �), whereas the behavior I expect to eventually have in Fenius is to pass the invalid bytes unchanged into the output. The only language I know of that matches my desired behavior is Elixir.)
Compared to lower-level languages (such as C):
Go is garbage collected, which not only makes my life easier during development, it also means I don’t have to implement a garbage collector for Fenius myself.
Go is memory-safe, type-safe (at least compared to C), and has no undefined behavior. (It does have some unspecified behavior in the memory model with respect to goroutine synchronization, but nothing comparable to C’s concept undefined behavior which basically means “if you make a misstep, the compiler will stab you in the back”.)
Go has first-class functions / closures, which makes a lot of things more convienient than they would be in C.
Go puts some incredible effort into letting you write top level declarations in any order and figuring out any dependencies between them automatically. For instance, you don’t have to care about the order in which mutually dependent structs or functions are declared, you can initialize global variables with non-constant expressions, and everything just works.
In summary, I see Go basically as a garbage-collected, memory-safe language with a small runtime, somewhat above C in abstraction level, but not much above. This can be either good or bad (or sometimes one and sometimes the other), depending on the requirements of your project.
(Another reason for using Go, which is unrelated to any of the features of the language itself, is that Go is used for a bunch of things where I work, so learning it would be useful for me professionally. And indeed, the experience I acquired working on the Fenius interpreter has been hugely useful at work so far.)
With all that said, Go does leave something to be desired in many respects, could be better designed in others, and just plain annoys me in others. Let’s investigate those.
Do repeat yourself
Go bills itself as a simple programming language, and simple it is. However, one thing it made me reflect about is that there is more than one way to go about simplicity. Scheme, for instance, also aims at being a simple programming language; and yet Scheme is far more expressive than Go. Now, “expressiveness” is a vague concept, so let’s try to make this more concrete. What I’m after here is an idea that might be called abstraction power: the ability to abstract repeating patterns in the code into reusable entities. Go leaves a lot to be desired in this department. Whereas Scheme is a simple language that gives you a basic set of building blocks from which you can build higher-level abstractions, Go is a simple language that pretty much forces everything to stay at the simple level. Whereas Scheme is simple but open-ended, “open-ended” is about the last word I would use to describe Go.
The thing is, Go is this way by design: whether or not you like this (and I don’t), it is an intentional rather than accidental part of the design of the language. And it does have some benefits: because there are fewer (no) ways to extend the language, it’s also easier to exclude certain behaviors when analyzing what a piece of code does. For example, recently at work, while trying to figure out how GORM works, someone wondered if GORM closed database connections automatically when the database handler went out of scope, and I was able to say I didn’t think that was possible, simply because there is no mechanism in Go that could be used to achieve that.1 Likewise, if you have something of the form someStruct.SomeField, you can be sure all this will do is read a memory location, not run arbitrary code. Of course, this has a flip side: anyone accessing someStruct.SomeField really depends on the struct having this field; it cannot be replaced by a property method in the future. You either have to live with that, or write an accessor method and always use that instead of accessing the field directly in the rest of the program, just like in plain ol’ Java.
The while problem
Go’s if has a two-clause version which allows you to initialize some variables and use them in the if condition. This works particularly well with the Go stategy of signaling errors and the results of some builtin constructs by returning multiple values. One common example is the “comma ok” idiom: the statement value, ok := someMap[key] sets value to the value of the key in the map (or a zero value if the key is not present), and ok to a boolean indicating whether the key was present in the map. Combined with the two-clause if form, this allows you to write:
if value, ok := someMap[key]; ok {
fmt.Printf("Key is present and has value %v\n", value)
} else {
fmt.Printf("Key is not present\n")
}
where ok is set in the first clause and used as a condition in the second. Likewise, switch also has a two-clause form.
Given that, you might expect there would be an analogous construct for loops. In fact, even in C and similar languages, one can write things like:
int ch;
while (ch = getchar(), ch != EOF) {
putchar(ch);
}
where the while condition assigns a variable and uses it in the loop condition. Surely Go can do the same thing, right?
Alas, it can’t. The problem is that Go painted itself into a corner by merging the traditional functions of while into the for construct. Basically, Go has a three-clause for which is equivalent to C’s for:
for i := 0; i < 10; i++ {
fmt.Println(i)
}
and a one-clause for which is equivalent to C’s while:
for someExpressionProducingABoolean() {
fmt.Println("still true")
}
but because of this, the language designers are reluctant to add a two-clause version, since it could easily be confused with the three-clause version – just type an extra ; at the end, and you have an empty third clause, which changes the behavior of the first clause to run just once before the loop rather than before every iteration. This could be easily avoided by having a separate while keyword in the language for the one- and two-clause versions, but I very much doubt this will ever be introduced, even in Go 2.
The issue comes up again every now and then. The solution usually offered is to use the three-clause for and repeat the same code in the first and third clauses, i.e., the equivalent of doing:
for (ch = getchar(); ch != EOF; ch = getchar()) {
putchar(ch)
}
i.e., “do repeat yourself”, or using a zero-clause for (which is equivalent to a while (true)) and an explicit break to get out of the loop. Incidentally, in the thread above, one of the Go team members replies that this kind of thing is not possible in other C-like languages either, but as we saw above, C actually can handle this situation because C has the comma operator and assignment is an expression, not a statement, which allows you to write stuff like while (ch = getchar(), ch != EOF), whereas Go neither has the comma operator, nor does it have assignment as an expression. I’m not arguing that it should have these, but rather that the lack of these elements makes a two-clause while more desirable in Go than it is in C.
Iteration, but not for you
There are many operations that are only available for builtin types, and you cannot implement them for your custom types. Consider, for example, iteration: Go has an iteration construct that looks like this:
for key, value := range iterableThing {
fmt.Printf("The key is %v, and the value is %v", key, value)
}
but it only works for arrays/slices, maps, strings and channels; you cannot make your own types iterable. Given that Go has interfaces, it would be easy for the language to include a standard Iterator interface which user-defined types could implement; but that’s not the case. (On a second thought, that’s actually not possible because Go does not have generics, and the return type of the iterator depends on the thing being iterated over.) If you want to write any sort of custom iteration, you will have to make do with regular function calls, a problem that is aggravated by the lack of a two-clause while (as seen above), which might allow you to test if there are more elements and get the next element at the same time.
Generics, but not for you
This is one of the most frequent complaints people have about Go. Go has no form of parametric polymorphism (a.k.a. generics): there is no way, for example, to define a function that works on lists of X for any type X, or to define a new type “binary tree” parameterized by the type of the elements you want to store in the tree.
If you are defining a new container data type and you want to be able to store elements of any type inside it, one option is to define the container’s elements as having type interface{}, i.e., the empty interface, which is satisfied by every type. This is roughly equivalent to using Object in Java. By doing this, you give up any static type safety when dealing with the container’s elements, and you have to cast the elements back to their original type when extracting them from the container, so basically you are left with a dynamically-typed language except with more boilerplate. The alternative, of course, is to repeat yourself and just write multiple versions of the functions and data structures you need, specialized for the types you happen to need.
Another option, seriously offered as an alternative by the language designers, is to write a code generator to generate specialized versions of the functions and data structures you need. No, Go does not have macros; what this entails is actually writing a program yourself that spits out a .go file with the content you want. Besides being much more work and being harder to maintain (although there are projects around that can do this for you; you just have to make sure to run the damn program every time you make changes to the original struct), it does not really help distributing libraries containing generic types.
Now, the funny thing is that the builtin types (arrays, slices, maps and channels) are type-parametric, and there is a number of builtin functions in Go, such as append and copy, that are generic as well, so, once again, Go has this feature, because it’s useful, but it’s only available for the builtin types and functions. This special-casing of builtin types is one of the most annoying aspects of Go’s design to me.
Now, unlike some fervorous Go proponents, the language designers themselves do recognize the lack of generics as a problem, and have done so for a long time; they have just been unsure how best to add them to Go’s design and afraid of adding in a bad design and then being stuck with supporting it forever, since Go makes strong guarantees about backwards compatibility, which is all perfectly reasonable. It looks like Go 2 will likely come with support for generics; we just don’t really know when that will happen.
Error handling
This is another classic of Go complaints, and with reason – it’s the other main problem that is serious enough to be recognized by the language designers, and may get better in Go 2. Until that happens, though, we are stuck with the Go 1 style of error handling.
In Go, errors are typically reported by returning multiple values. For example, a function like os.Open returns two values: an open file handler (which may be nil if an error occurred and the file could not be opened), and an error value indicating which error, if any, has happened. Typical use looks like this:
func doSomethingWithFile() int {
file, err := os.Open("/etc/passwd")
if err != nil {
log.Panicf("Error opening file: %v", err)
}
// ... do something with file ...
return 42;
}
or you can make your function return an error value itself, so you can pass it on for the caller to handle:
func doSomethingWithFile() (int, error) {
file, err := os.Open("/etc/passwd")
if err != nil {
return 0, err
}
// ... do something with file ...
return 42, nil
}
There are many problems with this approach. The most obvious one is that this quickly becomes a repetitive pile of if err != nil { return nil, err } after anything that may return an error, which distracts from the actual business logic. There is no way to abstract this repetition away, since you can’t pass the result of a multiple-values function as an argument to another function without assigning it to variables first, and a subfunction would not be able to return from the main function anyway. Macros could help here, but Go does not have them.
The second problem is that you don’t return either a value or an error (as you would do with Rust’s Result type, which is either an Ok(some_result) or an Err(some_error)); you return both a value and an error, which means you still have to return a value even when there is no value to return. For reference types, you can return nil; for other types, you typically return the zero value of that type (e.g., 0 for integers, "" for strings, a struct with zero-valued fields, etc.) The zero value is often a perfectly valid value that can occur in non-error situations as well, so if you make a mistake in handling the error, you may end up silently passing a zero value as a valid value to the rest of the program, rather than blowing up like an exception would.
This is partly mitigated by the fact that in Go it is an error to declare a variable and not use it, so you are forced to do something with the err you just created – unless an err already exists in scope, in which case your value, err := foo() will just reuse the existing err and no error will be generated if you don’t do anything with it. Moreover, functions that only have side-effects but don’t return anything other than an error (or do return some other value but the value is rarely used) are not protected by this. Perhaps the most common example are the fmt.Print* functions, which return the number of bytes written and an error value, but I’ve never seen this error value handled – it would become an utter mess if you were to do the if err != nil { ... } rigmarole after every print, so no one does, and print errors just get silently ignored by the vast majority of programs.
The third problem is that a function returning an error type does not really tell you anything about which errors it can return. This is also a problem with exceptions in most languages, but Go’s approach to error values feels even more unstructured. Consider for example the net package: it has a zillion little functions, most of which can return an error; almost none of them document which errors they can return. At least in POSIX C (which uses an even more primitive error value system, typically returning -1 and setting a global errno variable to the appropriate error code), you have manpages listing every possible error you can get from the function. In Go, I suppose the usual strategy is to find out the errors you care about and handle these, and pass the ones you don’t recognize up to the caller. That’s basically the strategy of exceptions, except done manually by you, with a lot of repetitive clutter in the code.
To be fair, the situation can be somewhat ameliorated through strategic use of the panic/recover mechanism, which is like exceptions except you’re not supposed to use them like exceptions. panic is usually used for fatal situations that mean the program cannot proceed. For situations that are supposed to be recoverable, you’re supposed to use error values. Now, what counts as recoverable or not depends on the circumstances. In general, you don’t want to call panic from a library (unless you hit an assertion violation or some other indicator of a bug), because you want library users to be able to treat the errors produced by your library. But in application code, where you know which situations are going to be handled and which are not, you can often use panic more liberally to abort on situations where execution cannot proceed and reduce the set of possible error values you pass up to the caller to only those the caller is expected to handle. Then you can use recover as a catch-all for long-running programs, to log the error and keep running (the Gin web framework, for instance, will automatically catch panics, log them and return a 500 to the client by default). I don’t know if this is considered idiomatic Go or not, but I do know that it makes code cleaner in my experience.
There is also precedent for using panic for non-local exits in the standard library: the encoding/json package uses panic to jump out of recursive calls when encountering an error, and then recover to turn the panic into a regular error value for users of the library.
No inheritance
Go has no inheritance; instead, it emphasizes the use of interfaces and composition. This is an interesting design choice, but it does cause problems sometimes. So far I have been in two situations where having something akin to an “abstract struct” from which I could inherit would have made my code simpler.
The first situation was in the Fenius interpreter: the abstract syntax tree (AST) generated by the parser has 8 different types of nodes, each of which is a struct type, some of which have subfields that are AST nodes themselves (for example, an AstBlock contains a list of AST nodes representing statements inside the block). To handle this, I define an AST interface which every node type implements. Now, one thing that every AST node has in common is a Location field. But an interface cannot require a satisfying type to have specific fields, only specific methods. Therefore, if I want the location of an AST node to be accessible regardless of its type, the only option I have is to add a Location() method to the interface (which I actually call Loc(), because I cannot have a field and a method with the same name), and implement it for each node type, so I have 8 identical method definitions of the form:
func (ast AstIdentifier) Loc() Location { return ast.Location }
in the code, one for each node type.
The second situation was in the web project at work, where I implemented a simple validation package to validate incoming JSON request bodies. In this package, I define a bunch of types representing different types of fields, such as String, Integer, Boolean, etc. Usage looks like this:
var FormValidator = validation.Map{
"name": validation.String{Required: true, MaxLength: 50},
"age": validation.Integer{Required: false, MinValue: 0},
}
All of these types have in common a boolean Required field. But again, since there is no inheritance, given a validator type there is no generic way for me to access the Required field. The only way is to implement a method returning the field for every validator type (or to use reflection and give up type safety).
Now, Go has an interesting feature, which is that you can embed other types in a struct, and you can even access the fields and methods of the embedded struct without naming it explicitly, so in principle I could do something like:
type BaseValidator struct {
Required bool
}
type String struct {
BaseValidator
MaxLength int
}
and now if I instantiate a String struct s, I can even write s.Required without naming the embedded struct! This could solve my problem, except that when initializing the struct, I cannot write just String{Required: true}: I have to write String{BaseValidator: BaseValidator{Required: true}}, which ruins my pretty Map definition.
Another thing that could solve my problem is writing a constructor function for the String type, but since Go does not have keyword arguments, that does not look pretty either. The only solution that looks pretty in the client code is to repeat myself in the package code.
No love for unfinished programs
In Go, it is a compilation error to define a variable and not use it, or to import a module and not use it. I do think it’s worthwhile to ensure that these things are not present in finished code (the one that goes to code review and gets deployed); that’s why we have linters. But requiring it during development is a pain in the ass. Say you are debugging a piece of code. Comment out something to see what happens? Code does not compile because a variable is not in use. Or you add some debug prints, run the code, see what happens, comment out the debug print, run again… code does not compile because you import fmt and don’t use it. These seemingly minor but frequent annoyances break your flow during development.
There are lots of interesting invariants that are useful to ensure are respected in finished programs, but which will be violated at various points during development, between the time you check out the repository and the time you have a new version ready to be deployed. It is my long-standing position that running unfinished programs is a useful thing to be able to do; this is a topic I might revisit in a future blog post. It is okay when a language rejects an incomplete program for technical reasons (e.g., the implementation cannot ensure run-time safety for code that calls non-existent functions, or calls a function with the wrong argument types). What annoys me is when a language goes out of its way to stop you from running code that it would otherwise be perfectly capable of running. Java’s checked exceptions and Go’s unused variable/import checks fall into this category. This could be easily solved by having a compiler switch to disable those checks during development, but alas, no.
At the same time, a struct constructor with missing fields is not an error, not even a warning, so if you forget a field, or add a new field to the struct and forget to update some place that constructs it, you get no help from the language; not even golint will tell you about it. (Yes, there are useful use cases for omitting struct fields, but I would expect at least a linter option to detect this.)
One-letter identifiers are the norm
And this is enshrined in the Go Code Review Comments page from the Go wiki:
Variable names in Go should be short rather than long. This is especially true for local variables with limited scope. Prefer
ctolineCount. PreferitosliceIndex.
Prefer c to lineCount? Why? It is general wisdom that code is read more often than it’s written, so it pays off to use descriptive variable names. It may be super clear for you, today, that c is a line count, but what about people new to the code base, or your future self 6 months from now? Is there any clarity gained by using c instead of lineCount? Is the code simpler?
As for i instead of sliceIndex… well, sure, since sliceIndex says very little about the slice’s purpose anyway. Depending on the context, there may be a better name than both i and sliceIndex to give to this variable. But I do grant that i may be an okay name for a slice index in a simple loop (although slice indexes don’t really appear that much anyway, since you can iterate over the values directly).
Testing
The only good thing I can say about Go’s testing infrastructure is that it exists; that’s about it. It is afflicted by Go’s obsession with single-letter identifiers (it defines types such as testing.T for tests, testing.B for benchmarks, testing.M for main test context). It provides no assert functions; you’re supposed to write an explicit if and panic to indicate test failures. (There is a popular library called Testify that provides asserts and also shows diffs between expected and found values.)
Despite doing very little, it also does too much. For instance, it caches test results by default (!). You can disable this behavior: “The idiomatic way to disable test caching explicitly”, I quote, “is to use -count=1.” (!!) It also runs tests from different packages in parallel by default, which makes for all sorts of fun if your tests use a database – the main one being spending a day figuring out why your tests don’t work, since this fact is not particularly prominent in documentation, i.e., it is not something you are likely to find out unless you are specifically looking for it. (You can disable parallelism, or use one of various third-party packages with different solutions to tests involving databases.)
The attitude
This one is very subjective, and not related to the language itself, but it just rubs me wrong when I see the Go designers speaking of Go as if it truly stood out from the crowd. Even when recognizing other languages, they seem to want to position Go as a pioneer in a great new wave of programming languages. From the Go FAQ:
We were not alone in our concerns. After many years with a pretty quiet landscape for programming languages, Go was among the first of several new languages—Rust, Elixir, Swift, and more—that have made programming language development an active, almost mainstream field again.
The Go project started by the end of 2007 and went public in 2009. Was the programming language landscape really that silent in the preceding years? Without doing any research other than checking the dates on Wikipedia, I can think of D (2001), Groovy (2003), Scala (2004), F# (2005), Vala (2006), Clojure (2007), and Nim (2008). So no, we were not in any kind of programming language dark ages before Go came along inaugurating a great renaissance of programming languages.
Recently I watched a video in which Rob Pike speaks of the fact that Go numeric constants work like abstract numbers without a specific type, so you can use 1 in a place expecting an int or a byte or a float64 without relying on type conversion rules, as a “relatively novel idea”. Guys, Haskell has had this at least since 1990. These ideas are not new, you have just been oblivious to the rest of the world.
Of course, Go does bring its own share of new ideas, and new ways to combine existing ideas. It just annoys me when they see themselves as doing something truly exceptional and out of the ordinary.
So why do I keep using this language?
And yet, despite all of the above, I still think Go was a good choice for implementing the Fenius interpreter, and I still think it’s a good choice in a variety of situations. So I think it’s appropriate to finish this post with some counterpoints to the above. Why do I keep using Go, despite all of the above problems?
First of all, it gets the job done. It is often the case that practical considerations, often having more to do with a language’s runtime and environment than with the language itself, lead to the choice of a given language for a job. For example, PHP has a terrible language design, but it’s super easy to deploy, so it makes sense to choose PHP for some tasks in some circumstances, even though there are plenty of better languages available. As for Go, regardless of any of the problems mentioned before, it does give me a lightweight memory-safe garbage-collected runtime, native self-contained executables, and does not try to hide the operating system from me. These characteristics make Go a good choice for my particular use case. (I should also note that, despite the above comparison with PHP, a lot of thought has been put into Go’s design, even if I disagree with many of the design choices.)
Second, in almost every respect in which Go is bad, C is even worse. So if you come to Go with a perspective of “I want something like C but less annoying”, Go actually delivers. And I would rather program in Go than in C++, even though C++ does not have many of the problems mentioned above, because the problems it does have are even worse. When I think from this perspective, I’m actually glad Go exists in this world, because it means I have fewer reasons to write C or C++.2
In fact, when you realize that Go came about as a reaction to C++, the relentless obsession with (a certain kind of) simplicity makes a lot more sense. C++ is a behemoth of a language, and it gets bigger with every new standard. Go is not only a very simple language, it makes it hard to build complex abstractions on the top of it, almost like a safeguard against C++-ish complexity creeping in. One can argue the reaction was too exaggerated, but I can understand where they are coming from.
There is a final bit of ambivalent praise I want to give Go, related to the above. I think Go embodies the Unix philosophy in a way no other recently designed language that I know of does. This is not an unambiguously good thing, mind you; it brings to my mind the worse is better concept, an interesting view of Unix and C by someone from outside of that tradition (and an essay with a fascinating story in itself). But Go had key Unix people among its designers – Ken Thompson (the inventor of Unix himself) and Rob Pike (who worked on Plan 9) – and it shows. For good and for bad, Go is exactly the kind of language you would expect Unix people to come up with if they sat down to design a higher-level successor to C. And notwithstanding all my misgivings about the language, I can respect that.
_____
1 Recently I learned it is possible to set a finalizer on an object, but they are not deterministic or related to scoping. I do find it a bit surprising that Go has finalizers, though.
2 If I did not need garbage collection, Rust would be a good option for this project as well. But as I mentioned in the beginning, I do need a garbage collector because Fenius is garbage-collected. If I were to implement it in a non-garbage-collected language, I would have to write a garbage collector for Fenius myself, whereas with Go or other garbage-collected languages, I can get away with relying on the host language’s garbage collector. I think of Rust and Go as complementary rather than in opposition, but that’s maybe a topic for another post.
My terrible nginx rules for cgit
2020-08-16 12:40 +0100. Tags: comp, unix, web, in-english
I’ve been using cgit for hosting my Git repositories since about the end of 2018. One minor thing that annoys me about cgit is that the landing page for repositories is not the about page (which shows the readme), but the summary page (which shows the last commits and repository activity). This is a useful default if you are visiting the page of a project you already know (so you can see what’s new), but not so much for someone casually browsing your repos.
There were (at least) two ways I could solve this:
I could change the cgit source code to use the about page as a default. This would require figuring out all parts to change, and keeping my own patched version of cgit. Or…
I could come up with a pile of nginx rules to map the external URLs I want (e.g.,
/code/<repo-name>/) into cgit’s own URLs (e.g.,/cgit/<repo-name>/about/).
I went with the second option.
Things are not so simple, however: even if I map my external URLs into cgit’s internal ones, cgit will still generate links pointing to its own version of the URLs. So the evil masterplan is to have two root locations:
/code/, which exposes the URLs the way I want them, translates them to cgit’s URLs, and passes the translated versions to cgit;/cgit/, which redirects cgit-style URLs to the corresponding/code/URLs. This way, cgit can still generate links to its own version of the URLs, and they will get translated back to the external URLs when the user follows the links.
In the rest of this post, I will go through the nginx rules I used. You can find them here if you would like to see them all at once.
The cgit FastCGI snippet
We will need four different rules for the /code location. All of them involve passing a translated URL to cgit, which involves setting up a bunch of FastCGI variables, most of which are identical in all rules. So let’s start by creating a file in /etc/nginx/snippets/fastcgi-cgit.conf which we can reuse in all rules:
fastcgi_pass unix:/run/fcgiwrap.socket; fastcgi_param QUERY_STRING $query_string; fastcgi_param REQUEST_METHOD $request_method; fastcgi_param CONTENT_TYPE $content_type; fastcgi_param CONTENT_LENGTH $content_length; fastcgi_param REQUEST_URI $request_uri; fastcgi_param DOCUMENT_URI $document_uri; fastcgi_param SERVER_PROTOCOL $server_protocol; fastcgi_param GATEWAY_INTERFACE CGI/1.1; fastcgi_param SERVER_SOFTWARE nginx/$nginx_version; fastcgi_param REMOTE_ADDR $remote_addr; fastcgi_param REMOTE_PORT $remote_port; fastcgi_param SERVER_ADDR $server_addr; fastcgi_param SERVER_PORT $server_port; fastcgi_param SERVER_NAME $server_name; # Tell fcgiwrap about the binary we’d like to execute and cgit about # the path we’d like to access. fastcgi_param SCRIPT_FILENAME /usr/lib/cgit/cgit.cgi; fastcgi_param DOCUMENT_ROOT /usr/lib/cgit;
These are standard CGI parameters; the only thing specific to cgit here is the SCRIPT_FILENAME and DOCUMENT_ROOT variables. Change those according to where you have cgit installed in your system.
The /code/ rules
Now come the interesting rules. These go in the server { ... } nginx section for your website (likely in /etc/nginx/sites-enabled/site-name, if you are using a Debian derivative). Let’s begin by the rule for the landing page: we want /code/<repo-name>/ to map to cgit’s /<repo-name>/about/:
location ~ ^/code/([^/]+)/?$ {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /cgit;
fastcgi_param PATH_INFO $1/about/;
}
The location line matches any URL beginning with /code/, followed by one or more characters other than /, followed by an optional /. So it matches /code/foo/, but not /code/foo/bar (because foo/bar has a /, i.e., it is not “one or more characters other than /”). The foo part (i.e., the repo name) will be accessible as $1 inside the rule (because that part of the URL string is captured by the parentheses in the regex).
Inside the rule, we include the snippet we defined before, and then we set two variables: SCRIPT_NAME, which is the base URL cgit will use for its own links; and PATH_INFO, which tells cgit which page we want (i.e., the <repo-name>/about page). Note that the base URL we pass to cgit is not /code, but /cgit, so cgit will generate links to URLs like /cgit/<repo-name>/about/. This is important because later on we will define rules to redirect /cgit URLs to their corresponding /code URLs.
The second rule we want is to expose the summary page as /code/<repo-name>/summary/, which will map to cgit’s repo landing page:
location ~ ^/code/([^/]+)/summary/$ {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /cgit;
fastcgi_param PATH_INFO $1/;
}
Again, the principle is the same: we match /code/foo/summary/, extract the foo part, and pass a modified URL to cgit. In this case, we just pass foo/ without the summary, since cgit’s repo landing page is the summary.
The third rule is a catch-all rule for all the other URLs that don’t require translation:
location ~ ^/code/(.*) {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /cgit;
fastcgi_param PATH_INFO $1;
}
That is, /code/ followed by anything else not matched by the previous rules is passed as is (removing the /code/ part) to cgit.
The /cgit/ rules
Now we need to do the mapping in reverse: we want cgit’s links (e.g., /cgit/<repo-name>/about) to redirect to our external version of them (e.g., /code/<repo-name>/). These rules are straightforward: for each of the translation rules we created in the previous session, we add a corresponding redirect here.
location ~ ^/cgit/([^/]+)/about/$ {
return 302 /code/$1/;
}
location ~ ^/cgit/([^/]+)/?$ {
return 302 /code/$1/summary/;
}
location ~ ^/cgit/(.*)$ {
return 302 /code/$1$is_args$args;
}
[Update (2020-11-05): The last rule must have a $is_args$args at the end, so that query parameters are passed on in the redirect.]
The cherry on the top of the kludge
This set of rules will already work if all you want is to expose cgit’s URLs in a different form. But there is one thing missing: if we go to the cgit initial page (the repository list), all the links to repositories will be of the form /cgit/<repo-name>/, which our rules will translate to /code/<repo-name>/summary/. But we don’t want that! We want the links in the repository list to lead to the repo about page (i.e., /code/<repo-name>/, not /cgit/<repo-name>/). So what do we do now?
The solution is to pass a different base URL to cgit just for the initial page. So we add a zeroth rule (it has to come before all other /code/ rules so it matches first):
location ~ ^/code/$ {
include snippets/fastcgi-cgit.conf;
fastcgi_param SCRIPT_NAME /code;
fastcgi_param PATH_INFO /;
}
The difference between these and the other rules is that we pass SCRIPT_NAME with the value of /code instead of /cgit, so that in the initial page, the links are of the form /code/<repo-name>/ instead of /cgit/<repo-name>/, which means they will render cgit’s /<repo-name>/about/ page instead of /<repo-name>/.
Beautiful, huh?
Caveats
One thing you have to ensure with these rules is that every repo has an about page; cgit only generates about pages for repos with a README, so your links will break if your repo doesn’t have one. One solution for this is to create a default README which cgit will use if the repo does not have a README itself. For this, I have the following settings in my /etc/cgitrc:
# Use the repo readme if available. readme=:README.md # Default README file. Make sure to put this file in a folder of its own, # because all files in the folder become accessible via cgit. readme=/home/elmord/cgit-default-readme/README.md
EOF
That’s all I have for today, folks. If you have comments, feel free to, well, leave a comment.
Type parameters and dynamic types: a crazy idea
2020-07-24 22:19 +0100. Tags: comp, prog, pldesign, fenius, in-english
A while ago I wrote a couple of posts about an idea I had about how to mix static and dynamic typing and the problems with that idea. I've recently thought about a crazy solution to this problem, probably too crazy to implement in practice, but I want to write it down before it flees my mind.
The problem
Just to recapitulate, the original idea was to have reified type variables in the code, so that a generic function like:
let foo[T](x: T) = ...
would actually receive T as a value, though one that would be passed automatically by default if not explicitly specified by the programmer, i.e., when calling foo(5), the compiler would have enough information to actually call foo[Int](5) under the hood without the programmer having to spell it out.
The problem is how to handle heterogeneous data structures, such as lists of arbitrary objects. For example, when deserializing a JSON object like [1, "foo", true] into a List[T], there is no value we can give for T that carries enough information to decode any element of the list.
The solution
The solution I had proposed in the previous post was to have a Dynamic type which encapsulates the type information and the value, so you would use a List[Dynamic] here. The problem is that every value of the list has to be wrapped in a Dynamic container, i.e., the list becomes [Dynamic(1), Dynamic("foo"), Dynamic(true)].
But there is a more unconventional possibility hanging around here. First, the problem here is typing a heterogeneous sequence of elements as a list. But there is another sequence type that lends itself nicely for this purpose: the tuple. So although [1, "foo", true] can't be given a type, (1, "foo", true) can be given the type Tuple[Int, Str, Bool]. The problem is that, even if the Tuple type parameters are variables, the quantity of elements is fixed statically, i.e., it doesn't work for typing an arbitrarily long list deserialized from JSON input, for instance. But what if I give this value the type Tuple[*Ts], where * is the splice operator (turns a list into multiple arguments), and Ts is, well, a list of types? This list can be given an actual type: List[Type]. So now we have these interdependent dynamic types floating around, and to know the type of the_tuple[i], the type stored at Ts[i] has to be consulted.
I'm not sure how this would work in practice, though, especially when constructing this list. Though maybe in a functional setting, it might work. Our deserialization function would look like (in pseudo-code):
let parse_list(input: Str): Tuple[*Ts] = {
if input == "" {
()
# Returns a Tuple[], and Ts is implicitly [].
} elif let (value, rest) = parse_integer(input) {
(value, *parse_list(rest))
# If parse_list(rest) is of type Tuple[*Ts],
# (value, *parse_list(rest)) is of type Tuple[Int, *Ts].
} ...
}
For dictionaries, things might be more complicated; the dictionary type is typically along the lines of Dict[KeyType, ValueType], and we are back to the same problem we had with lists. But just as heterogeneous lists map to tuples, we could perhaps map heterogeneous dictionaries to… anonymous records! So instead of having a dictionary {"a": 1, "b": true} of type Dict[Str, T], we would instead have a record (a=1, b=true) of type Record[a: Int, b: Bool]. And just as a dynamic list maps to Tuple[*Ts], a dynamic dictionary maps to Record[**Ts], where Ts is a dictionary of type Dict[Str, Type], mapping each record key to a type.
Could this work? Probably. Would it be practical or efficient? I'm not so sure. Would it be better than the alternative of just having a dynamic container, or even specialized types for dynamic collections? Probably not. But it sure as hell is an interesting idea.
Switching to the i3 window manager
2020-07-19 16:00 +0100. Tags: comp, unix, wm, emacs, in-english
After almost 3 years using EXWM as my window manager, I decided to give i3 a try. And after two weeks using it, I have to say I'm definitely sticking with it.
I had actually tried i3 years ago, but I had never used a tiling window manager before, and for some reason it didn't click for me at the time. This time, after a long time using EXWM (which I picked up more easily at the time since all the commands were the regular Emacs window/buffer commands I already knew), i3 was quite easy to pick up. So here I am.
Why not EXWM?
EXWM has a lot going for it, mainly from the fact of running in Emacs, and therefore benefitting from the general powers that all things built on Emacs have: it's eminently hackable and customizable (and you can generally see the results of your hacks without even restarting it), and can be integrated in your Emacs workflow in various ways (I gave some examples in my previous EXWM post).
However, it also has some drawbacks. EXWM does not really do much in the way of managing windows: essentially, EXWM just turns all your windows into Emacs buffers, and the window management tasks proper (splitting, deciding which Emacs window will display a new X window, etc.) is the built-in window management Emacs uses for its own windows. Which can of course be customized to death, but is not particularly great for large numbers of windows, in my opinion.
Another problem with EXWM is that if Emacs hangs for any reason (e.g., waiting for TRAMP to open a remote SSH file, or syntax highlighting choking on an overly long line in a JSON file or a Python shell), your whole graphical session freezes, because EXWM does not get an opportunity to react to X events while Emacs is hung doing other stuff. This will happen more or less often depending on the kinds of tasks you do with Emacs. (Also, if you have to kill Emacs for any reason, you kill your entire graphical session, though this can be avoided by starting Emacs like this in your .xsession:
until emacs; do :; done
an idea I wish I had had earlier.)
Finally, EXWM is glitchy. Those glitches don't manifest too often, and it's hard to separate the glitches that come naturally with it from the ones caused by my own hacks, but the fact is that I got tired of the glitchiness and hanging, and also I was lured by i3's tabs support, so I decided to switch.
First steps into i3
The first time you start i3, it presents you with a dialog asking whether you want to use Alt or Win (the 'Windows' key, a.k.a. Super) as the modifier key for i3 shortcuts. I recommend choosing Super here, since it will avoid conflicts with shortcuts from applications. i3 will then generate a config file at ~/.config/i3/config.
The generated config file contains all the default keybindings; there are no extra keybindings other than those listed in this file. This is good because you can peruse the config file to have a general idea of what keybindings exist and how their corresponding commands are expressed. That being said, the i3 User's Guide is quite good as well, and you should at least skim over it to get an idea of i3's abilities.
One peculiar thing about the standard keybindings is the use of Super+j/k/l/; to move to the window to the left, down, up, and right, respectively. That's shifted one key to the right of the traditional h/j/k/l movement commands used by Vim and some other programs. The documentation justifies this as being easier to type without moving away from the home row (and also, Super+h is used to set horizontal window splitting), but I ended up changing this to Super+h/j/k/l simply for the convenience of having bindings similar to what other applications use (and then moving horizontal splitting to Super+b, right beside Super+v for vertical splitting).
Unlike EXWM or some other window managers, the i3 config file is not a full-fledged programming language, so it's not as flexible as those other WMs. However, i3 has a trick up its sleeve: the i3-msg program, which allows sending commands to a running i3. Thanks to i3-msg, you can do tasks that require more of a programming language (e.g., conditional execution) by writing small shell scripts. For example, I have a script called jump-to-terminal.sh, which is just:
#!/bin/bash i3-msg '[class="terminal"] move container to workspace current, focus' | grep -q true || x-terminal-emulator
i.e., try to find an open terminal window and move it to the current workspace; if the operation does not succeed (because there is no open terminal window), open a new terminal. I can then bind this script to a shortcut in the i3 config file. (I've actually changed script later to not move the window to the current workspace, but it shows how you can string multiple i3 commands together applying to the same window.)
Containers, tabs, and more
i3 uses the concept of containers to organize windows: windows themselves are containers (containing the actual X11 window), but the whole workspace is itself a container that can be split into multiple subcontainers that can be arbitrarily nested. Containers can either use a split layout (windows are tiled horizontally or vertically within the container), or a tabbed layout (i3 shows a tab bar at the top of the container, and each contained window is a tab), or a stacked layout (which is the same as the tabbed layout but the tab titles are placed in separate lines rather than side-by-side). You can switch the layout of the current container with the shortcuts Super+w (tabbed), Super+s (stacked), and Super+e (split, toggling between horizontal and vertical tiling).
(Note that what i3 calls "horizontal split container" is a split container with horizontal tiling orientation, i.e., windows are laid out side-by-side. This can be confusing if you expect "horizontal split" to mean that the splitting line will be horizontal. This is the same terminology that Emacs uses for window splitting, but the opposite of Vim.)
Containers can be arbitrarily nested, and you can have different layouts in each subcontainer. For example, you could have your workspace divided into two horizontally-tiled containers, and have a tabbed layout in one of the subcontainers. Note that because of this, it's important to know which container you have selected when you use the layout-changing commands. The colors of the borders tell you that, but it takes a while to get used to paying attention to it. i3 comes with a pre-defined binding Super+a to select the parent of the current container, but not one to select a child; I have found it useful to bind Super+z to focus child for this purpose.
Unnesting containers
The commands Super+v and Super+h (Super+b in my modified keymap) select a tiling orientation for new windows opened in the current container. (Again, the border colors tell you which mode is active.) It implicitly turns the current container into a nested container, so that new windows will become siblings of the current window. It is very easy to create nested containers by accident in this way, especially when you are just starting with i3. Those show up like i3: H[emacs] in the window title (i.e., a horizontally-tiled container containing just an emacs window), and you can even get into multiple levels of nested containers with a single window inside. In these situations, it is useful to have a command to move the current window back to its parent container. Surprisingly, i3 does not have a built-in command for that, but it is possible to concoct one from existing commands (based on this StackExchange answer):
# Move container to parent bindsym $mod+Shift+a mark subwindow; focus parent; focus parent; mark parent; [con_mark="subwindow"] focus; move window to mark parent; [con_mark="subwindow"] focus; unmark
What this does is to use i3 marks (which are like Vim marks, allowing you to assign labels to windows) to mark the current window and its parent's parent, and then moving the window to inside its parent's parent (i.e., it becomes a sibling of its current parent).
The status bar
In EXWM, I had recently implemented a hack to display desktop notifications in the Emacs echo area. I hate desktop notifications appearing on the top of what I'm doing (especially when I'm coding), and I had most of them disabled for this reason until recently, but Slack notifications are useful to see at work. With this hack, I could finally have non-obtrusive desktop notifications. I was only going to switch to i3 if I could find a way to have similar functionality in it.
i3 does not exactly have an echo line, but it does have a desktop bar which shows your workspaces to the left, tray icons to the right, and the output of a status command in the middle. The status command can be any command you want, and the status line shows the last line of output the command has printed so far, so the command can keep updating it. i3bar actually supports two output formats: a plain-text one in which every line is displayed as-is in the status line, and a JSON-based format which allows specifying colors, separators and other features in the output.
This means that you can write a script to listen for D-Bus desktop notifications and print them as they come, together with whatever else you want in the status line (such as a clock and battery status), and blanking them after a while, or when a 'close notification' message is received. I have done just that, and it works like a charm. (It requires python3-pydbus to be installed.) The only problem with this is that the content of the status line is aligned to the right (because it is meant to be used for a clock and stuff like that), and there is no way to make it aligned to the left, so I actually pad the message to be shown with spaces to a length that happens to fit my monitor. It is sub-optimal, but it works well enough.
Conclusion
I'm pretty happy with the switch to i3. Although I've lost the deep integration with Emacs, it has actually been an improvement even for my Emacs usage, since i3 tabs supplement Emacs's lack of tabs better than any tabbing package I have seen for Emacs. (Having tabs for all programs, including things like Evince, is really nice.) If you are interested in tiling window managers and are willing to spend a few days getting used to it, I definitely recommend it.
Type parameters and dynamic types
2020-05-30 17:27 +0100. Tags: comp, prog, pldesign, fenius, in-english
In the previous post, I discussed an idea I had for handling dynamic typing in a primarily statically-typed language. In this post, I intend to first, describe the idea a little better, and second, explain what are the problems with it.
The idea
The basic idea is:
- Functions can take type arguments as well as value arguments.
- Type arguments are passed as actual concrete values that can be consulted at run-time to determine what methods the type supports.
- Any value argument without an explicitly declared type gets an implicit type argument associated with it.
For example, consider a function signature like:
let f[A, B](arg1: Int, arg2: A, arg3: B, arg4): Bool = ...
This declares a function f with two explicit type parameters A and B, and four regular value parameters arg1 to arg4. arg1 is declared with a concrete Int type. arg2 and arg3 are declared as having types passed in as type parameters. arg4 does not have an explicit type, so in effect it behaves as if the function had an extra type parameter C, and arg4 has type C.
When the function is called, the type arguments don't have to be passed explicitly; rather, they will be automatically provided by the types of the expressions used as arguments. So, if I call f(42, "hello", 1.0, True), the compiler will implicitly pass the types Str and Float for A and B, as well as Bool for the implicit type parameter C.
In the body of f, whenever the parameters with generic types are used, the corresponding type parameters can be consulted at run-time to find the approprate methods to call. For example, if arg2.foo() is called, a lookup for the method foo inside A will happen at run-time. This lookup might fail, in which case we would get an exception.
This all looks quite beautiful.
The problem
The problem is when you introduce generic data structures into the picture. Let's consider a generic list type List[T], where T is a type parameter. Now suppose you have a list like [42, "hello", 1.0, True] (which you might have obtained from deserializing a JSON file, for instance). What type can T be? The problem is that, unlike the case for functions, there is one type variable for multiple elements. If all type information must be encoded in the value of the type parameter, there is no way to handle a heterogeneous list like this.
Having a union type here (say, List[Int|Str|Float|Bool]) will not help us, because union types require some way to distinguish which element of the union a given value belongs to, but the premise was for all type information to be carried by the type parameter so you could avoid encoding the type information into the value.
For a different example, consider you want to have a list objects satisfying an interface, e.g., List[JSONSerializable]. Different elements of the list may have different types, and therefore different implementations of the interface, and you would need type information with each individual element to be able to know at run-time where to find the interface implementation for each element.
Could this be worked around? One way would be to have a Dynamic type, whose implementation would be roughly:
record Dynamic(
T: Type,
value: T,
)
The Dynamic type contains a value and its type. Note that the type is not declared as a type parameter of Dynamic: it is a member of Dynamic. The implication is that a value like Dynamic(Int, 5) is not of type Dynamic[Int], but simply Dynamic: there is a single Dynamic type container which can hold values of any type and carries all information about the value's type within itself. (I believe this is an existential type, but I honestly don't know enough type theory to be sure.)
Now our heterogeneous list can simply be a List[Dynamic]. The problem is that to use this list, you have to wrap your values into Dynamic records, and unwrap them to use the values. Could it happen implicitly? I'm not really sure. Suppose you have a List[Dynamic] and you want to pass it to a function expecting a List[Int]. We would like this to work, if we want static and dynamic code to run along seamlessly. But this is not really possible, because the elements of a List[Dynamic] and a List[Int] have different representations. You would have to produce a new list of integers from the original one, unwrapping every element of the original list out of its Dynamic container. The same would happen if you wanted to pass a List[Int] to a function expecting a List[Dynamic].
All of this may be workable, but it is a different experience from regular gradual typing where you expect this sort of mixing and matching of static and dynamic code to just work.
[Addendum (2020-05-31): On the other hand, if I had an ahead-of-time statically-typed compiled programming language that allowed me to toss around types like this, including allowing user-defined records like Dynamic, that would be really cool.]
EOF
That's all I have for today, folks. In a future post, I intend to explore how interfaces work in a variety of different languages.
Types and Fenius
2020-05-19 21:35 +0100. Tags: comp, prog, pldesign, fenius, in-english
Hello, fellow readers! In this post, I will try to write down some ideas that have been haunting me about types, methods and namespaces in Fenius.
I should perhaps start with the disclaimer that nothing has really happened in Fenius development since last year. I started rewriting the implementation in Common Lisp recently, but I only got to the parser so far, and the code is still not public. I have no haste in this; life is already complicated enough without one extra thing to feel guilty about finishing, and the world does not have a pressing need for a new programming language either. But I do keep thinking about it, so I expect to keep posting ideas about programming language design here more or less regularly.
So, namespaces
A year ago, I pondered whether to choose noun-centric OO (methods belong to classes, as in most mainstream OO languages) or verb-centric OO (methods are independent entities grouped under generic functions, as in Common Lisp). I ended up choosing noun-centric OO, mostly because classes provide a namespace grouping related methods, so:
- You don't have to deal with name conflicts if two classes define independent methods with the same name;
- You don't have to import each method separately. In fact you don't even have to import the class: if you have an object, you can call its methods without even knowing which class it belongs to (in a dynamic language context).
This choice has a number of problems, though; it interacts badly with other features I would like to have in Fenius. Consider the following example:
Suppose I have a bunch of classes that I want to be able to serialize to JSON. Some of these classes may be implemented by me, so I can add a to_json() method to them, but others come from third-party code that I cannot change. Even if the language allows me to add new methods to existing classes, I would rather not add a to_json() method to those classes because they might, in the future, decide to implement their own to_json() method, possibly in a different way, and I would be unintentionally overriding the library method which others might depend on.
What I really want is to be able to declare an interface of my own, and implement it in whatever way I want for any class (much like a typeclass in Haskell, or a trait in Rust):
from third_party import Foo
interface JSONSerializable {
let to_json()
}
implement JSONSerializable for Foo {
let to_json() = {
...
}
}
In this way, the interface serves as a namespace for to_json(), so that even if Foo implements its own to_json() in the future, it would be distinct from the one I defined in my interface.
The problem is: if I have an object x of type Foo and I call x.to_json(), which to_json() is called?
One way to decide that would be by the declared type of x: if it's declared as Foo, it calls Foo's to_json(), and JSONSerializable's to_json() is not even visible. If it's declared as JSONSerializable, then the interface's method is called. The problem is that Fenius is supposed to be a dynamically-typed language: the declared (static) type of an object should not affect its dynamic behavior. A reference to an object, no matter how it was obtained, should be enough to access all of the object's methods.
Solution 1: Interface wrappers
One way to conciliate things would be to make it so that the interface wraps the implementing object. By this I mean that, if you have an object x of type Foo, you can call JSONSerializable(x) to get another object, of type JSONSerializable, that wraps the original x, and provides the interface's methods.
Moreover, function type declarations can be given the following semantics: if a function f is declared as receiving a parameter x: SomeType, and it's called with an argument v, x will be bound to the result of SomeType.accept(v). For interfaces, the accept method returns an interface wrapper for the given object, if the object belongs to a class implementing the interface. Other classes can define accept in any way they want to implement arbitrary casts. The default implementation for class.accept(v) would be to return v intact if it belongs to class, and raise an exception if it doesn't.
Solution 2: Static typing with dynamic characteristics
Another option is to actually go for static typing, but in a way that still allows dynamic code to co-exist more or less transparently with it.
In this approach, which methods are visible in a given dot expression x.method is determined by the static type of x. One way to see this is that x can have multiple methods, possibly with the same name, and the static type of x acts like a lens filtering a specific subset of those methods.
What happens, then, when you don't declare the type of the variable/parameter? One solution would be implicitly consider those as having the basic Object type, but that would make dynamic code extremely annoying to use. For instance, if x has type Object, you cannot call x+1 because + is not defined for Object.
Another, more interesting solution, is to consider any untyped function parameter as a generic. So, if f(x) is declared without a type for x, this is implicitly equivalent to declaring it as f(x: A), for a type variable A. If this were a purely static solution, this would not solve anything: you still cannot call addition on a generic value. But what if, instead, A is passed as a concrete value, implicitly, to the function? Then our f(x: A) is underlyingly basically f(x: A, A: Type), with A being a type value packaging the known information about A. When I call, for instance, f(5), under the hood the function is called like f(5, Int), where Int packages all there is to know about the Int type, including which methods it supports. Then if f's body calls x+1, this type value can be consulted dynamically to look up for a + method.
Has this been done before? Probably. I still have to do research on this. One potential problem with this is how the underlying interface of generic vs. non-generic functions (in a very different sense of 'generic function' from CLOS!) may differ. This is a problem for functions taking functions as arguments: if your function expects an Int -> Int function as argument and I give it a A -> Int function instead, that should work, but underlyingly an A -> Int takes an extra argument (the A type itself). This is left as an exercise for my future self.
Gradual typing in reverse
One very interesting aspect of this solution is that it's basically the opposite of typical gradual typing implementations: instead of adding static types to a fundamentally dynamic language, this adds dynamic powers to a fundamentally static system. All the gradual typing attempts I have seen so far try to add types to a pre-existing dynamic language, which makes an approach like this one less palatable since one wants to be able to give types to code written in a mostly dynamic style, including standard library functions. But if one is designing a language from scratch, one can design it in a more static-types-friendly way, which would make this approach more feasible.
I wonder if better performance can be achieved in this scenario, since in theory the static parts of the code can happily do their stuff without ever worrying about dynamic code. I also wonder if boxing/unboxing of values when passing them between the dynamic and static parts of the code can be avoided as well, since all the extra typing information can be passed in the type parameter instead. Said research, as always, will require more and abundant funding.
« Mais recentes / Newer posts | Mais antigos / Older posts »